
Guide to Context Engineering
Building smarter, more aware systems...

In the initial wave of excitement around LLMs, the focus was on "prompt engineering" the craft of writing the perfect question to get a brilliant answer. However, as we build more complex, production-grade AI applications, it's become clear that this is only a small part of a much larger challenge. The true differentiator for creating reliable, scalable, and intelligent AI systems lies in a more sophisticated discipline: Context Engineering.

Todays edition of Where’s The Future in Tech provides a detailed exploration of Context Engineering, moving beyond individual prompts to discuss the architectural patterns and strategies required to build production ready AI systems.
The Paradigm Shift from Prompt to Context
The transition from prompt engineering to context engineering represents a fundamental shift in how we design and build with LLMs. It's the evolution from treating the model as a simple question-answer machine to architecting an entire information ecosystem around it.

What is Context Engineering?
While prompt engineering focuses on crafting the specific input for a single task, Context Engineering is the discipline of designing, managing, and optimizing the entire information space an LLM sees before it generates a response.
Think of it like this: prompt engineering is like asking a very specific question in a conversation. Context engineering is like choosing the room for that conversation, deciding who else is in it, what books are on the shelves, and what notes are on the table. It’s about ensuring the model has everything it needs to perform its task effectively.
The Components of a Modern Context Window
The "context" we engineer is far more than just the user's query. It's a dynamic assembly of multiple information types, all competing for limited space in the model's working memory (the context window). A well-engineered context can include:

System instructions: High-level directives that define the model's persona, rules, and behavior (e.g., “You are an expert legal assistant”).
Conversation history: A record of previous turns in the dialogue to maintain coherence.
Retrieved knowledge: External facts pulled from documents, databases, or APIs to ground the model's response in reality. This is where techniques like Retrieval-Augmented Generation (RAG) come into play.
Tool definitions and outputs: Descriptions of available tools (like a calculator or a web search API) and the results from recent tool calls.
User preferences and Long-Term memory: Information about the user that persists across sessions, such as their communication style or previous support tickets.
Output schemas: Instructions, often in formats like JSON, that constrain the model's output to a specific structure.
The core challenge of context engineering is to dynamically select, format, and combine these components into a single, coherent package that maximizes the model's performance for a given task, all while respecting the finite size of the context window.
The Three Pillars of Context
To manage this complexity, we can think of the engineered context as having three distinct dimensions: Instructional, Knowledge, and Operational. Mastering each is essential for building reliable systems.
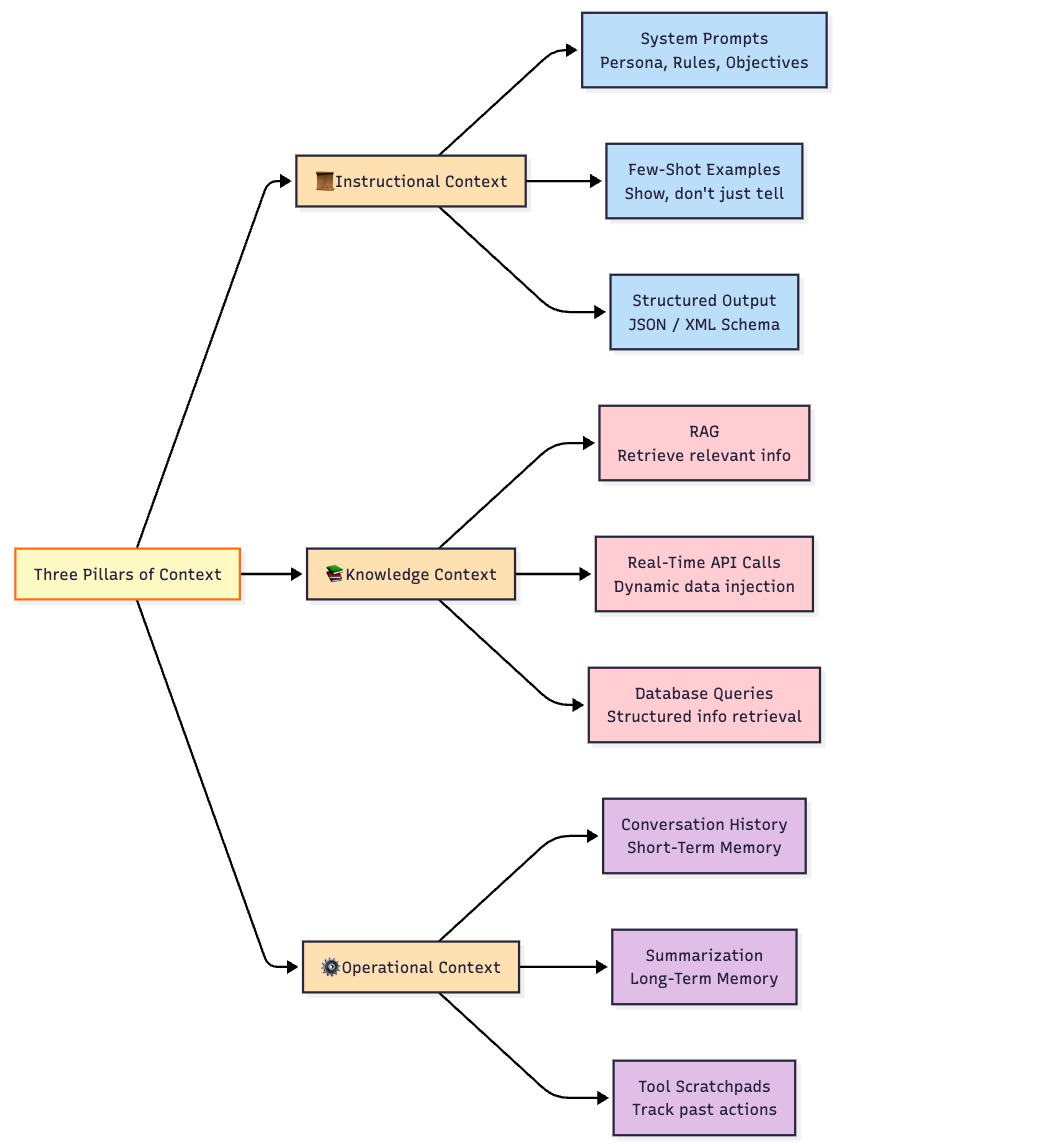
Pillar 1: Instructional Context
This layer defines how the agent should behave. It sets the ground rules for the interaction.
System prompts: A well-crafted system prompt is the foundation of instructional context. It establishes the model's persona, its constraints ("Answer only based on the provided sources"), and its objectives.
Few-Shot examples: Instead of just telling the model what to do, you can show it. Including a few examples of high-quality input-output pairs directly in the context is a powerful way to guide the model's behavior and output format without expensive fine-tuning.
Structured output formats: When you need a predictable, machine-readable output, you can provide an output schema (like a JSON template or XML tags) in the prompt. This instructs the model to structure its response according to your exact specifications, which is critical for integrating the LLM with other software components.
Pillar 2: Knowledge Context (What the Model Knows)
This layer provides the model with the factual information it needs to complete a task. Since LLMs have a knowledge cutoff and no access to your private data, this pillar is crucial for building useful applications.
Retrieval-Augmented Generation (RAG): RAG is the most common technique for providing knowledge context. It is a framework that retrieves relevant snippets of information from an external knowledge base (like a collection of company documents) and adds them to the prompt. This grounds the model in specific, verifiable facts, dramatically reducing hallucinations and allowing it to answer questions about proprietary or recent information. While often discussed as a standalone architecture, in the broader view of context engineering, RAG is a powerful implementation pattern for managing the "Knowledge Context" pillar.
Real-Time API calls: For information that is highly dynamic (e.g., stock prices, weather forecasts), the context can be augmented with real-time data fetched from external APIs. The system can be designed to recognize when it needs this data and make the appropriate API call, inserting the result into the context.
Database integration: For applications that need to reason over structured data, the system can query a database and include the results in the context. For example, a customer service bot could query a CRM to fetch a user's purchase history before generating a response.
Pillar 3: Operational Context (The State of the Interaction)
This layer manages the memory and flow of a multi-turn conversation or a complex, multi-step task.
Short-Term Memory (Conversation History)
Including recent dialogue turns in the context allows the model to maintain continuity, understand follow-up questions, and avoid repetitive clarifications.
Example: If a user asks, “What about tomorrow?”, the AI should know “tomorrow” refers to the event mentioned earlier not start from scratch.Long-Term Memory (Summarization)
Since the context window is limited, it’s not feasible to store entire conversation histories forever. Instead, summarization mechanisms periodically compress past interactions into a concise, fact-preserving summary.
This allows the model to:Recall decisions made earlier
Maintain user preferences over long sessions
Keep reasoning consistent even after dozens of messages
Scratchpads & Tool Output Memory
When an AI agent calls tools like a calculator, a database, or a web search the results of these actions should remain accessible in its working memory.
This “scratchpad” acts as a dynamic note-taking space, letting the model build upon earlier results instead of repeating actions or losing track of intermediate steps.Standardizing Operational Context with MCP
Today, most applications manually stitch together history, summaries, and tool outputs for each model call. This is fragile and inconsistent across platforms.
Model Context Protocol (MCP) aims to fix this by defining a standardized way to represent operational context.
With MCP:Conversation state, memory summaries, and tool usage can be shared in a portable, structured format.
Switching LLMs or moving between tools doesn’t mean rebuilding context pipelines from scratch.
Developers gain a predictable, interoperable foundation for complex multi-step interactions.
Advanced Strategies for Context Management
The finite nature of the context window is the central battleground for LLM application performance. Effective context engineering requires sophisticated strategies for managing this limited resource. These strategies can be grouped into four main categories: Write, Select, Compress, and Isolate.
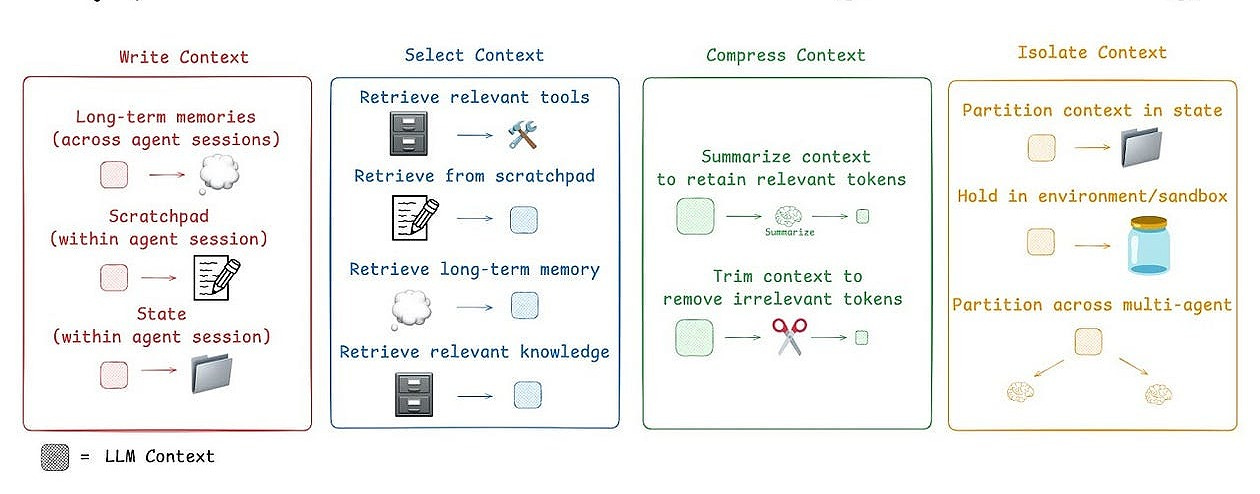
Write Context: Creating and Storing Context
This involves creating new contextual information that can be used later.
Generating memories: An LLM can be prompted to reflect on a conversation and generate a summary of key facts or user preferences. This summary can then be stored in a long-term memory system to be retrieved in future sessions.
Maintaining a Scratchpad: For complex tasks, an agent can be instructed to "think step-by-step" and write its reasoning process to a scratchpad. This scratchpad then becomes part of the context, allowing the agent to track its own work and avoid repeating mistakes.
Select Context: Choosing the Most Relevant Context
Rather than stuffing the context window with everything, we must intelligently select the most relevant information for the current task.
Advanced retrieval: When using RAG, simply retrieving the top
kdocuments is often not enough. Advanced techniques like Hybrid Search (combining semantic and keyword search) and Re-ranking (using a powerful cross-encoder to re-order an initial set of candidates) ensure that the knowledge added to the context is of the highest possible relevance.Selective Memory retrieval: Instead of including the entire conversation history, a system can perform a semantic search over past interactions to retrieve only the turns that are most relevant to the current user query.
Dynamic tool selection: For agents with many available tools, it's inefficient to include all tool definitions in every prompt. A more advanced approach is to use RAG to retrieve only the most relevant tool descriptions for the specific task at hand, which has been shown to dramatically improve tool selection accuracy.
Compress Context: Reducing Context Size Without Losing Signal
Compression techniques are vital for managing long-running conversations or processing large documents.
Context summarization: As mentioned earlier, using an LLM to summarize conversation history or large documents is a powerful compression technique. This is used effectively in products like Claude Code to manage long interactions.
Tool output pruning: The raw output from a tool call (e.g., a JSON blob from an API) can be very verbose. A compression step can strip away irrelevant information, retaining only the essential result (e.g., "Action: Search, Result: Found 3 documents").
Isolate Context: Preventing Context Contamination
Different types of context can interfere with each other, leading to errors. This is sometimes called context poisoning (a hallucination gets into the context), distraction (context overwhelms the model's training), or confusion (superfluous context influences the response).
State objects: A well-designed agent uses a structured state object to keep different types of context separate. For example, the full conversation history might be stored in one field, while only a concise summary is exposed to the LLM in the prompt, preventing the model from getting lost in irrelevant details.
Multi-Agent systems: A powerful isolation strategy is to break a complex task down and assign sub-tasks to different agents, each with its own isolated context window. For example, a "researcher" agent might have a context focused on web search tools, while a "writer" agent has a context focused on style guides and formatting instructions. This separation of concerns can lead to more reliable performance than a single agent trying to manage all context types at once.
Understanding the Scenario: A Customer's Order is Late
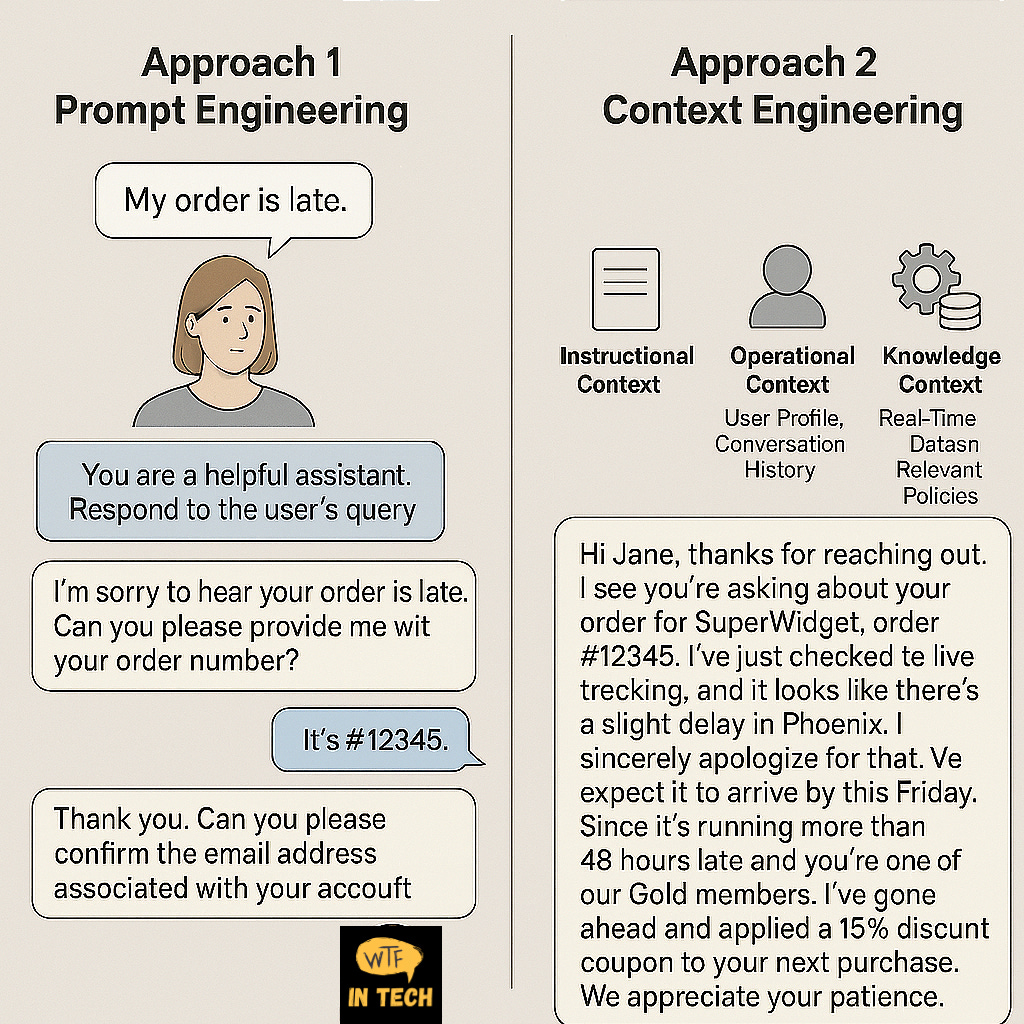
Imagine a customer, Jane, opens the chat window on the "Awesome Gadgets Inc." website and types:
"My order is late."
This simple, four-word sentence is the user prompt. How the AI responds depends entirely on the quality of its context.
Approach 1: Prompt Engineering Only
A system built with only basic prompt engineering would treat the user's message in isolation. It has no context beyond the words "My order is late."
The Prompt: The system might have a pre-written instruction like, "You are a helpful assistant. Respond to the user's query."
The Interaction:
AI: "I'm sorry to hear your order is late. Can you please provide me with your order number?"
Jane: "It's #12345."
AI: "Thank you. Can you please confirm the email address associated with your account?"
Jane: (Getting frustrated) "It's jane.doe@email.com."
AI: "Thank you. I see order #12345 is delayed. We apologize for the inconvenience."
The Result: This interaction is frustrating, repetitive, and inefficient. The AI has no awareness of who Jane is or what she's done, forcing her to do all the work. This is a classic example of a context failure.
Approach 2: Context Engineering
A system built with Context Engineering treats the user's prompt as just one piece of a much larger puzzle. Before the AI model (like Gemini) even generates a response, a sophisticated backend system runs to assemble the perfect context.
Here’s what happens in the seconds after Jane hits "Enter":
1. The System Gathers Context from Multiple Sources:
Instructional Context (The AI's Persona): The system starts with a detailed set of instructions.
"You are a senior customer support agent for 'Awesome Gadgets Inc.' You are empathetic, proactive, and empowered to solve problems. Your goal is to resolve the customer's issue in a single interaction if possible. Refer to the customer by their first name."
Operational Context (Memory & State): The system checks its memory.
It recognizes Jane is logged in, so it already knows her name and email.
It pulls her recent conversation history and sees she was looking at the tracking page for order #12345 just five minutes ago.
Knowledge Context (Tools & External Data): The system uses tools to dynamically fetch real-time information.
CRM API Call: It queries the customer database and retrieves Jane's profile: "Jane Doe, VIP Gold Member, 32 past orders."
Shipping API Call: Using the order number from the chat history, it queries the shipping partner's API: "Status: In Transit. Last Scan: Phoenix, AZ. Estimated Delivery: August 5th (2 days late)."
Internal Knowledge Base (RAG): The system performs a search on its internal policy documents with the query "late shipment policy for VIP Gold members." It retrieves the following key fact: "VIP Gold members are entitled to a 15% discount coupon for any shipment delayed by more than 48 hours."
2. The System Assembles the Final Context for the LLM:
The system now constructs a rich, detailed brief for the AI model. It's not just the user's four words; it's a full intelligence report:
System Instructions: You are a senior customer support agent...
User Profile: Customer is Jane Doe, a VIP Gold Member.
Conversation History: User was just viewing the tracking page for order #12345.
Real-Time Data:
Order #12345 contains one 'SuperWidget'.
Current shipping status is 'In Transit' and it is 2 days late.
Relevant Policies:
VIP Gold members get a 15% discount coupon for delays over 48 hours.
User Prompt: "My order is late."
3. The AI Generates a High-Quality Response:
Equipped with this comprehensive context, the AI can now generate a truly helpful and personalized response in its very first message:
AI: "Hi Jane, thanks for reaching out. I see you're asking about your order for the SuperWidget, order #12345. I've just checked the live tracking, and it looks like there's a slight delay in Phoenix. I sincerely apologize for that. We expect it to arrive by this Friday. Since it's running more than 48 hours late and you're one of our Gold members, I've gone ahead and applied a 15% discount coupon to your account for your next purchase. We appreciate your patience!"
This is the difference. Prompt engineering is about the user's initial question. Context engineering is about the entire system that dynamically gathers instructions, memory, and real-time knowledge to give the AI everything it needs to be truly intelligent and useful.
The Future: Agentic Systems and Long Context
Context engineering isn’t just a workaround for today’s models it’s the foundation of next-generation agentic AI systems. An AI agent’s real intelligence doesn’t come from a single prompt but from its ability to continuously orchestrate context planning, using tools, retrieving knowledge, and dynamically assembling the right information for every reasoning step.
Some wonder whether ultra-long context windows (1–2 million tokens) will make context engineering obsolete. In reality, they make it even more important:
Filtering still matters: A bigger context window is like having a massive warehouse for data. Without context engineering techniques especially retrieval and relevance scoring you still won’t know which “files” to bring to the model at the right time.
The “Lost in the Middle” problem persists: Even with huge windows, LLMs often struggle to effectively use information buried deep inside the context. Strategic placement and prioritization remain essential.
Cost and Latency: Processing millions of tokens is expensive and slow. Selecting, compressing, and structuring context is the only scalable way forward.
This is where agentic frameworks like LangGraph, DSPy step in, automating context assembly across multiple steps and tools. And with emerging standards like the Model Context Protocol (MCP), context will soon become portable and interoperable, making it easier to switch models or scale systems without rebuilding pipelines from scratch.
Ultimately, context engineering is the bridge from experimental AI to reliable, enterprise-ready intelligence. LLM performance is no longer just a model property it’s an emergent property of the entire information ecosystem we design around it. Mastering context is how we’ll unlock truly intelligent, proactive AI agents.

Until next time,
Stay curious, stay innovative and subscribe to us to get more such informative newsletters.
Read more of WTF in Tech newsletter:
Good info