
KV Cache in LLMs
Why fast language models don’t rethink everything from scratch and how KV Caching makes that possible

If you’ve ever wondered how modern LLMs like GPT-4, Claude, or LLaMA can hold multi-turn conversations, remember what you said 3000 tokens ago? there’s a silent architect behind the scenes: The Key-Value (KV) Cache.
The KV cache is the core performance enabler for fast, scalable, and efficient inference in autoregressive language models. It’s how ChatGPT doesn’t lose its train of thought mid-sentence. But despite its importance, the KV cache often remains a black box something ML engineers toggle on in HuggingFace configs, or system architects size for deployment, without fully understanding how it works under the hood.

In todays edition of Where’s The Future in Tech we’re diving in from scratch and I mean all the way down to the architecture level, let’s peel the layers.
Why KV Cache exists at all?
When you prompt an LLM to generate text, it doesn't "know" what came before unless you explicitly feed that context back into it. But reprocessing the entire input sequence every time you generate a new token is:
Computationally expensive (O(n²) for attention).
Slow for long prompts.
Redundant, because most of that work was already done.

What is the KV Cache
KV stands for Key-Value, and it refers to the core mechanics inside the self-attention layers of a Transformer. In simple terms, every time a token is processed by an attention layer, the model generates:

A Key vector: representing “What this token is about”
A Value vector: representing “What information this token carries”
When the model wants to predict the next token, it compares the current token's Query vector to all previous Keys to decide which tokens to attend to, then uses the corresponding Values to compute the final result.
What’s actually Cached?
When a transformer processes tokens (words or subwords), it passes them through a series of self-attention layers. In each of these layers, three things are computed:
→ Query (Q)
→ Key (K)
→ Value (V)
Now, here’s the magic: during generation, we don’t need to recompute the Key and Value vectors for all previously seen tokens. Instead, we cache them meaning we store the computed K and V tensors for all past tokens in memory, layer by layer.
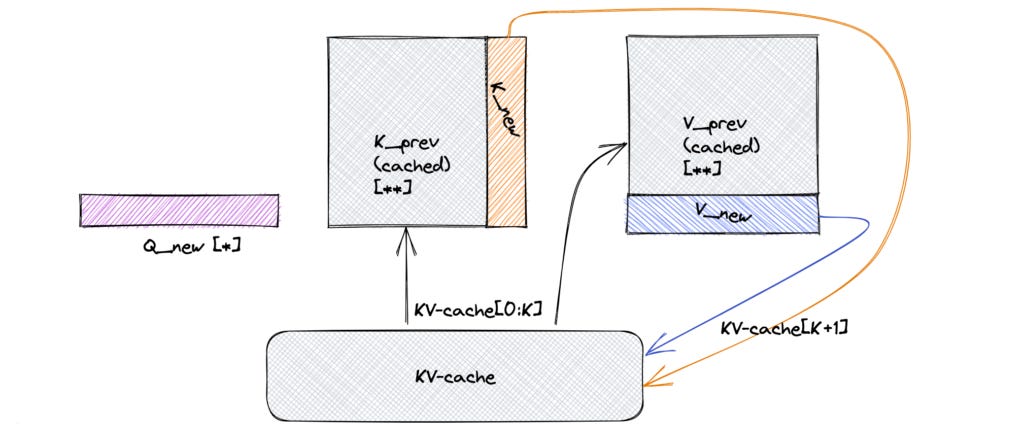
So what exactly gets cached?
Key vectors for all past tokens (per attention head, per layer)
Value vectors for all past tokens (same granularity)
Query vectors are not cached they are computed fresh for the current token.
Why? Because the Query depends on the current token’s embedding. But to calculate attention for that token, you need to compare its query against all previous keys, and blend the result with values. So those past K and V values? They're pure gold.
Without caching, you’d have to recompute the keys and values for every previous token at every generation step, which quickly becomes a nightmare for long sequences both in time and memory. Caching avoids that
What does this cache look like?
Think of it like a shelf of labeled folders.
Each transformer layer has its own set of KV pairs.
Each attention head within the layer stores a separate matrix of keys and values.
These matrices grow with each new token (like a dynamic sequence of snapshots).
It’s usually stored as two 4D tensors (one for keys, one for values), shaped like:
(batch_size, num_heads, sequence_length, head_dim)
“Okay, but how are those keys and values used during generation?”
To answer that, we need to step inside the most important room in the transformer house the self-attention mechanism. Let’s walk through it together, step by step, and see exactly how the model uses the cache to decide what to pay attention.
Self-Attention, decoded
Self-attention is where the model decides “what should I focus on right now?” and thanks to the KV cache, it can do that without re-reading the entire past like a forgetful goldfish. Let’s break down what happens at a single step during generation (say, when predicting the next token), with the cache already populated.

Get the current token’s embedding: The model receives the next token (or prompt fragment) as input let’s call it token t. The first thing it does is convert t into a dense vector using an embedding layer. This vector is the raw material for the next steps. This embedding is only for token t, not the full sequence remember, we’re in generation mode, and we’re doing things one token at a time.
Compute the Query (Q) for Token t:This embedded token passes through the current transformer layer to compute its Query vector. And just to reiterate we don’t cache this. Why? Because the query represents what this token is trying to look for in the context it’s the flashlight beam, not the bookshelf.
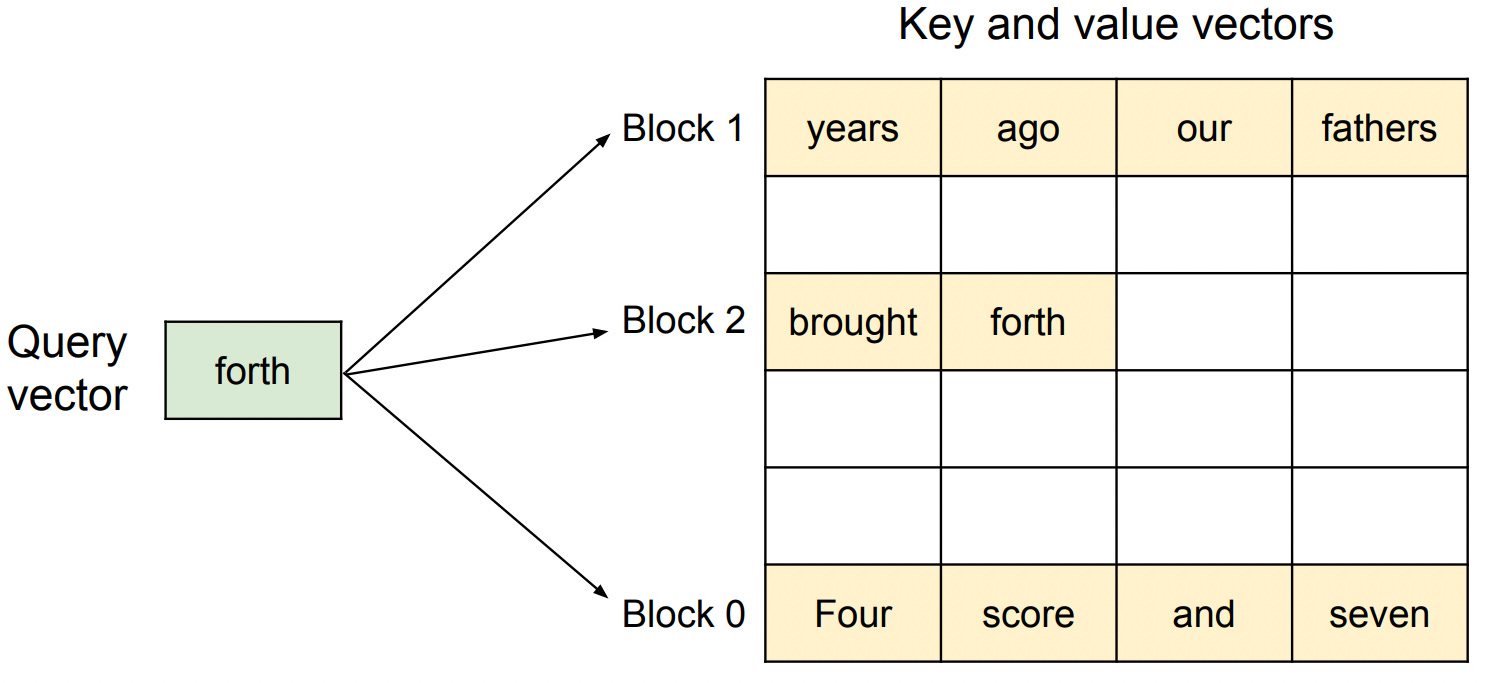
Fetch Cached Keys (K) and Values (V): Now the model pulls out the cached keys and values for all previous tokens from the KV Cache across every attention head, for this specific layer. These represent the “what was said before” in the conversation.
Keys → like tags summarizing each past token
Values → the rich information associated with those tokens
Compute Attention scores (Q × Kᵗ): The model computes the dot product of the current token’s Query with each past Key (via a QKᵗ operation). This gives a set of raw attention scores how relevant is each previous token to the one we’re generating now?
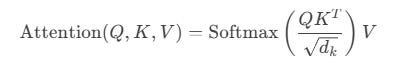
These scores are then scaled and softmaxed to turn them into a probability distribution. Basically: “Here’s how much attention I should pay to each past token.”
Weighted Sum of Values = The Context Vector: Once the model knows what to pay attention to (i.e., the attention weights), it uses them to blend the cached Value vectors. This results in a single context vector a rich, context-aware summary of what matters from the past, tailored for this specific token.
Add + Norm + Feed Forward: This context vector isn’t the final output just yet. It goes through the usual transformer finishing school:
Add & Layer Norm: Combined with residual connections
Feedforward Network (FFN): Further transformation
Repeat: Passed through the next layer (each with its own KV cache)
Generate the next token: After passing through all transformer layers, the final output vector hits a linear + softmax layer to predict the most likely next token and boom, generation continues. The new token’s K and V vectors are now cached, and the process repeats for the next step.
Where does KV Caching fit in?
During training, the model sees full sequences at once so there's no need to reuse anything. But during inference, when you’re generating one token at a time, recalculating every layer’s keys and values for all previous tokens becomes a performance nightmare. This is where KV Caching steps in at the heart of the token-by-token generation loop.
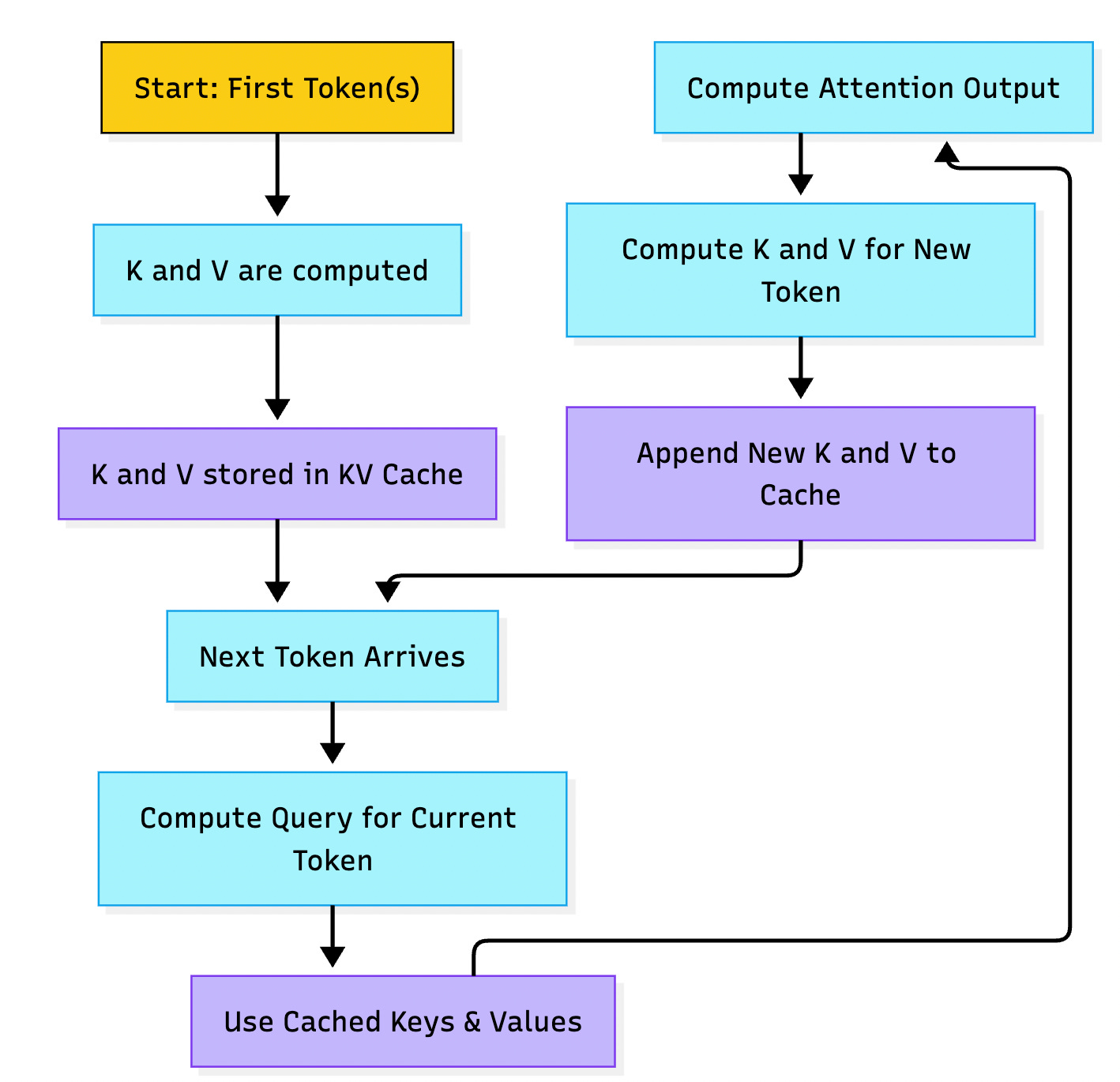
Here’s what happens:
First token(s) are processed normally K and V are computed and stored.
For every new token, only the query is calculated.
The model then uses the cached K and V from all previous tokens to compute attention.
The new token’s K and V are added to the cache, and the cycle continues.
How KV Caching optimizes inference
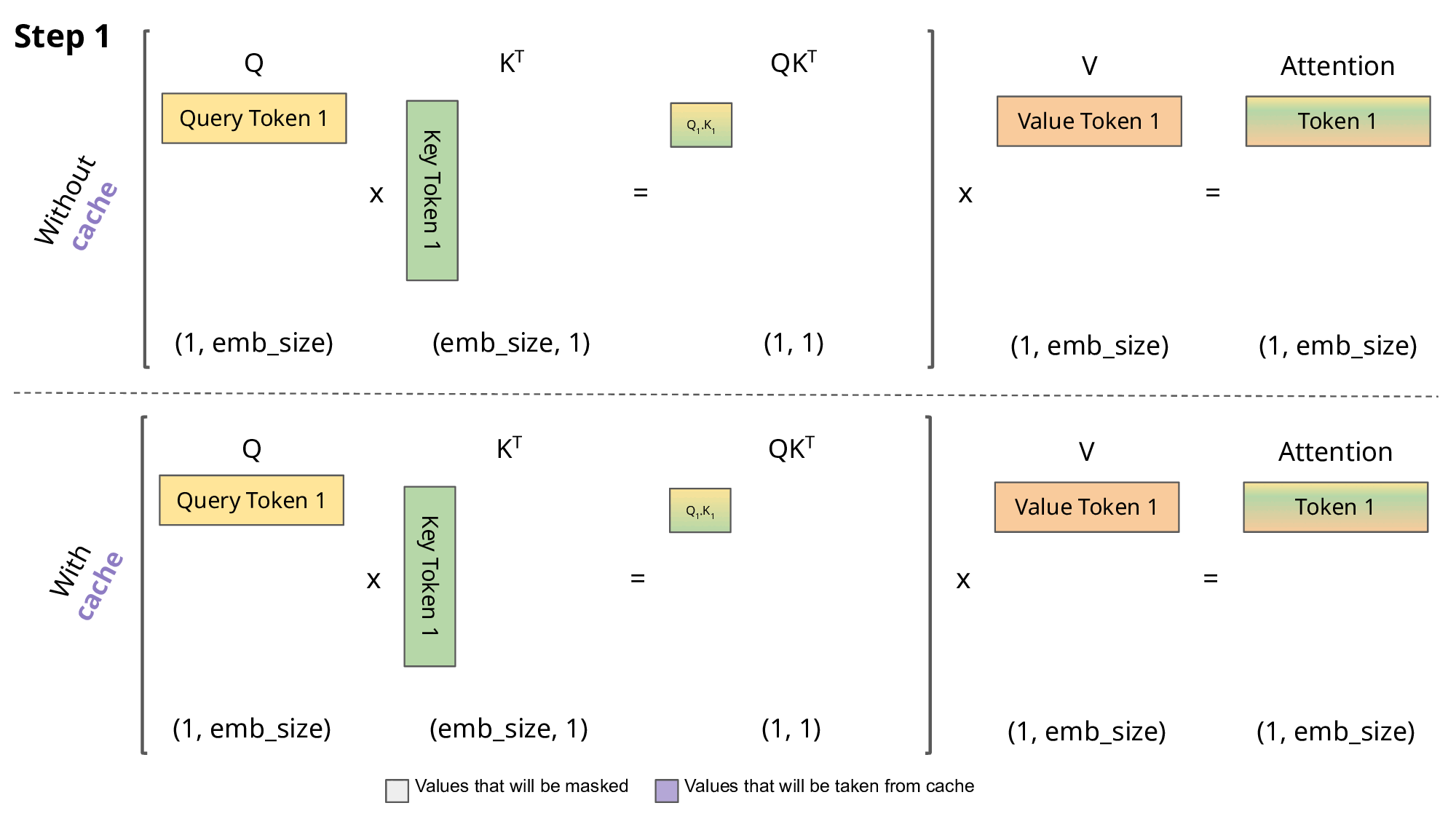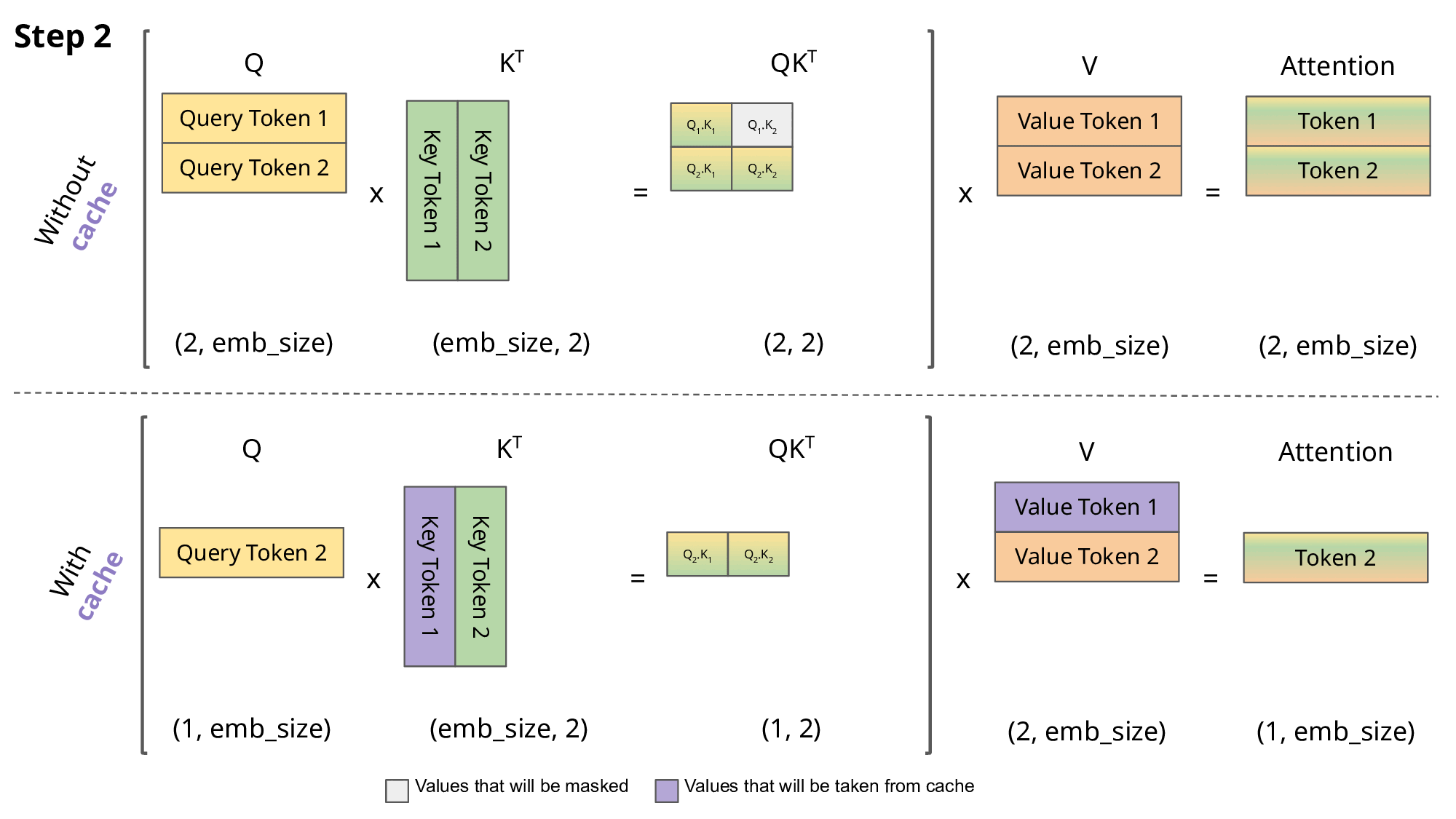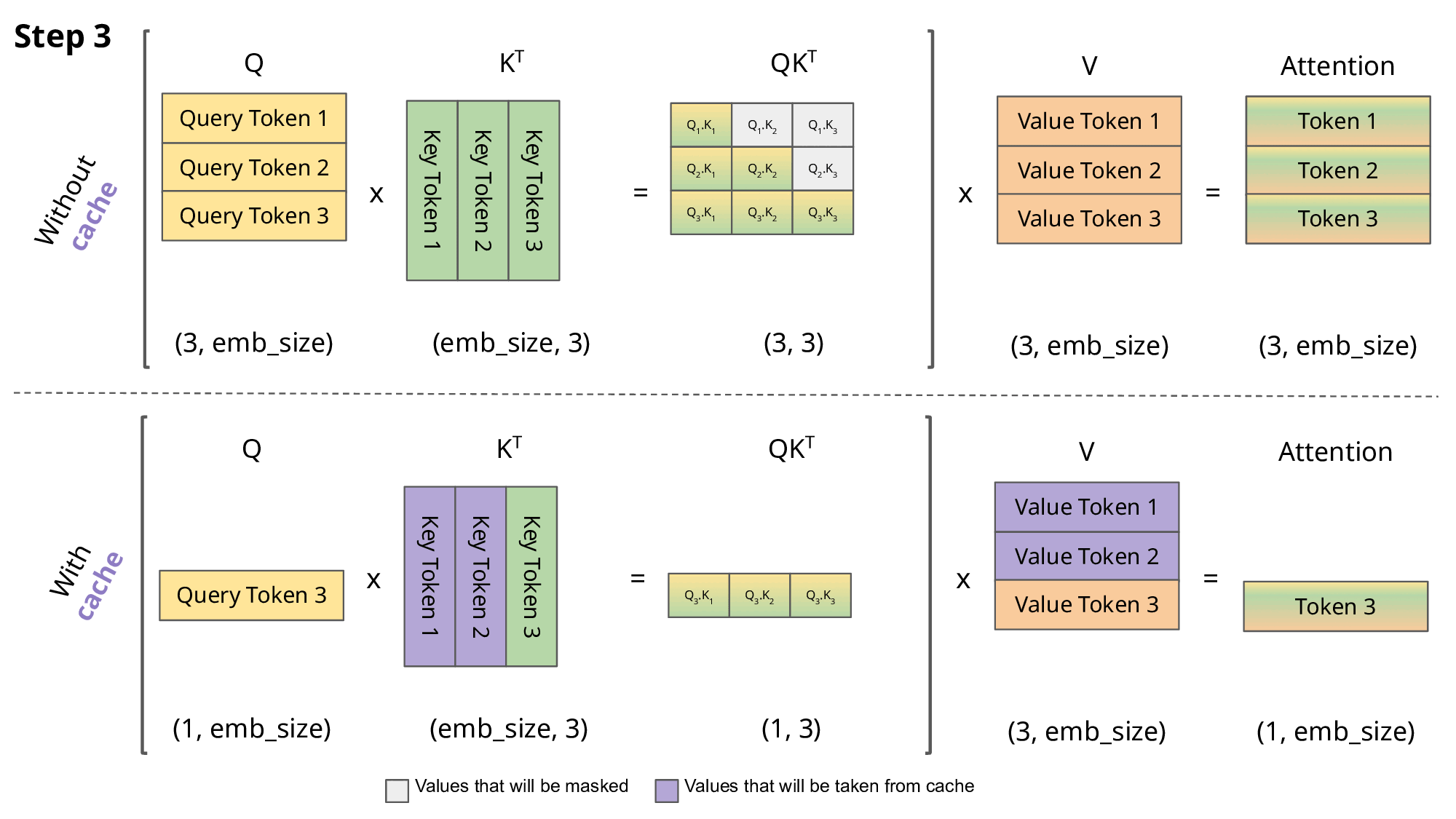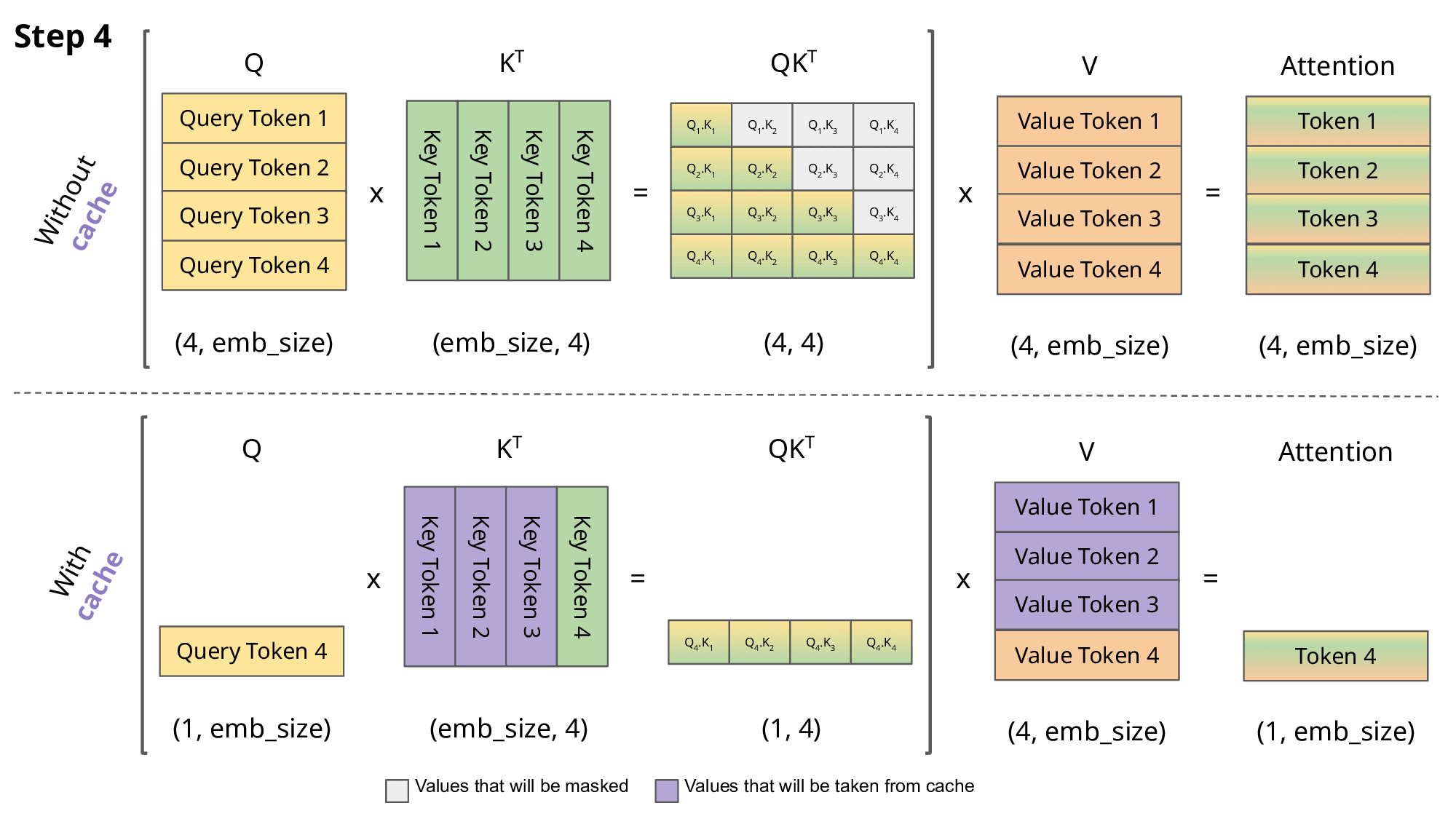
Without KV caching:
Every new token → recompute attention across all past tokens, in all layers, for all heads. For 1000 tokens, that’s ~500,000+ QK and KV ops across layers.
With KV caching:
Each new token only computes one Query, then performs a lookup on cached K and V. Time complexity shifts from O(n²) (quadratic) to O(n) (linear-ish) in practical terms.
Result?
Up to 10–30x speedup for long sequences.
Memory use becomes more predictable and manageable with the right strategy.
Generation becomes real-time which is why tools like ChatGPT or Claude feel fast, even with massive models behind them.
What happens inside the Cache: Layer by Layer
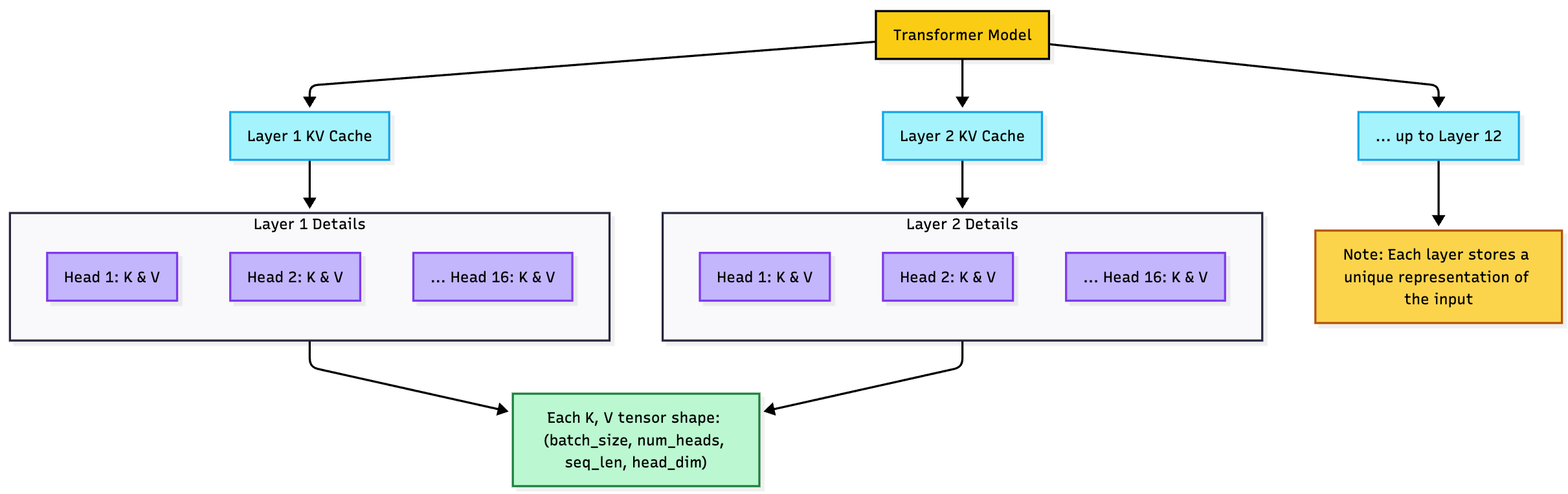
For every layer in the transformer:
There’s a separate KV cache.
Each attention head in the layer has its own keys and values.
These are stored as tensors with shape:
K, V → (batch_size, num_heads, sequence_length, head_dim)
So for a 12-layer model with 16 attention heads and a 512-token sequence, you're storing 12 × 2 × 16 = 384 individual matrices, each growing with sequence length. Why per-layer? Because each layer computes different representations. The K and V in layer 8 are not the same as those in layer 4 they reflect different abstraction levels of the input.
Challenges
KV Caching is fast but not free. Let’s look at some trade-offs.
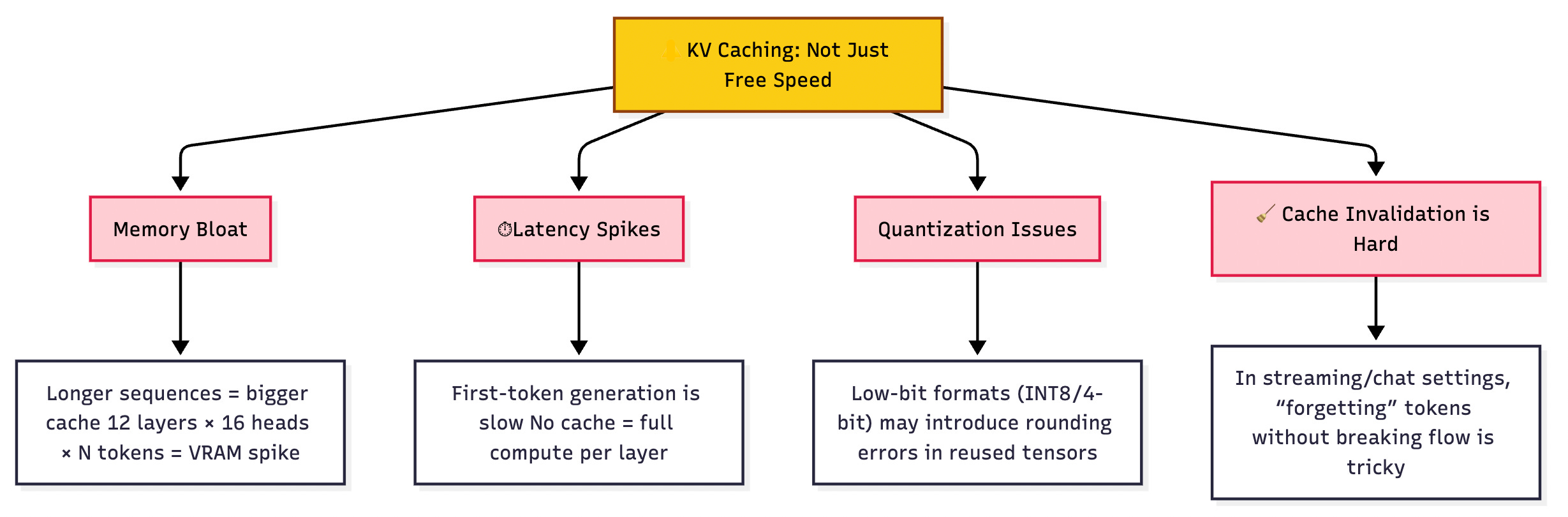
1. Memory bloat: The longer the sequence, the larger the cache. Multiply that by number of layers × heads, and your VRAM fills up fast. Even a modest model like LLaMA-7B can eat gigabytes of VRAM for a few thousand tokens if you don’t manage cache size smartly.
2. Latency spikes: First-token inference is slow there’s no cache yet. Once the cache is warmed up, generation speeds up. But that cold start can be noticeable.
3. Quantization edge cases: When using quantized models (e.g., INT8 or 4-bit), caching may introduce rounding errors. Some quant formats don’t play well with high-precision tensor reuse.
4. Cache invalidation: In streaming use-cases (chat apps, voice assistants), models sometimes need to "forget" part of the conversation but pruning a KV cache cleanly without corrupting the attention flow can be tricky.
FlashAttention, Paged KV, and Smart Caching Tricks
To scale models to massive lengths and keep latency low, we need more than just caching we need better caching. Here are some of the bleeding-edge optimizations:
FlashAttention: Rewrites attention as fused GPU kernels that reduce memory access bottlenecks. Instead of materializing big attention matrices, it computes them on the fly, layer-by-layer, using tiling making both training and inference faster.
Paged KV caching (Mistral’s Trick): Inspired by virtual memory, this splits the KV cache into pages of fixed size. Instead of growing unbounded, the model loads, evicts, and reuses cache pages like a mini operating system.
Ring Buffers & Sliding Windows: For models with limited context windows (e.g., 4K or 8K tokens), ring buffers recycle the oldest K/V entries once capacity is reached saving memory without breaking performance.
Smart Cache Eviction: Some experimental techniques rank tokens by semantic utility (e.g., based on entropy or relevance scores) and selectively prune low-value keys like an attention-aware LRU cache.
Conclusion
The future of caching won’t just be faster it’ll be smarter. Models will learn what to remember, what to forget, and how to compress the past into a more intelligent present. And in a world moving toward ever-larger context windows, KV Caching might just be the next frontier for making memory truly intelligent.
This is great insight thanks for sharing it.
is it possible to implement this in ANY framework? I know the plain API call implicitly does caching.. but for some reason i want this in a framework like langchain..NO i dont want semantic caching. i want THIS. does ANY framework offer this? dspy does caching. but again that is not kv caching..