

If you thought the RAG journey peaked in Part 2, where we met agents that plan (Agentic RAG), vision models that retrieve, and even tree-organized brains like RAPTOR think again. That was just the intermission.

In todays edition of Where’s The Future in Tech we will cover Part 3 of our “25 Types of RAG” series, we’re diving into the deep end with some of the most experimental, adaptive, and domain-specific RAG architectures out there.
Each type you’ll read about here from Auto-RAG to Graph-RAG is designed not just to retrieve relevant chunks but to rethink how retrieval interacts with memory, feedback, structure, and reasoning. Whether it's translation, cost efficiency, or multi-hop knowledge traversal these RAGs are built for real-world nuance.
So buckle up. The retrieval pipeline just got a PhD.
17. AUTO RAG – Autonomous Iterative Retrieval
Auto RAG is like that thoughtful friend who double-checks before giving an answer. It doesn’t just grab some documents and run with them it keeps an eye on what it’s writing, and if something feels off, it pauses, fetches better info, and only then continues. It’s smart, self-aware retrieval that knows when to dig deeper.
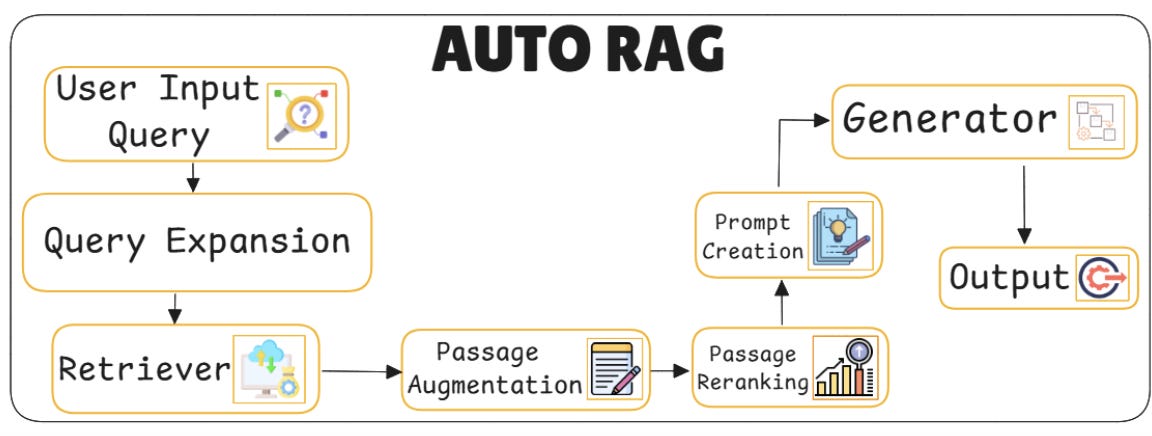
Key components:
Iterative retriever loop: Retrieval isn’t a one-time step it’s interleaved with generation. The model triggers multiple retrieval rounds mid-generation when it detects missing context or uncertain output.
Uncertainty detection: The generator tracks its confidence as it writes. If it senses ambiguity, it flags that moment and re-invokes the retriever to improve clarity and coherence.
Query evolution mechanism: Queries adapt with every iteration. Rather than repeat the same prompt, the model updates the retrieval input based on partial generations and attention patterns.
Self-Supervised retrieval control: Auto RAG learns when to stop or repeat retrieval through training. It uses generation success as feedback no manual tuning required.
18. CORAG – Cost-Constrained Retrieval-Augmented Generation
CO-RAG brings budgeting to retrieval. Instead of endlessly fetching more documents, it works within a fixed resource envelope balancing retrieval quality with compute and time.
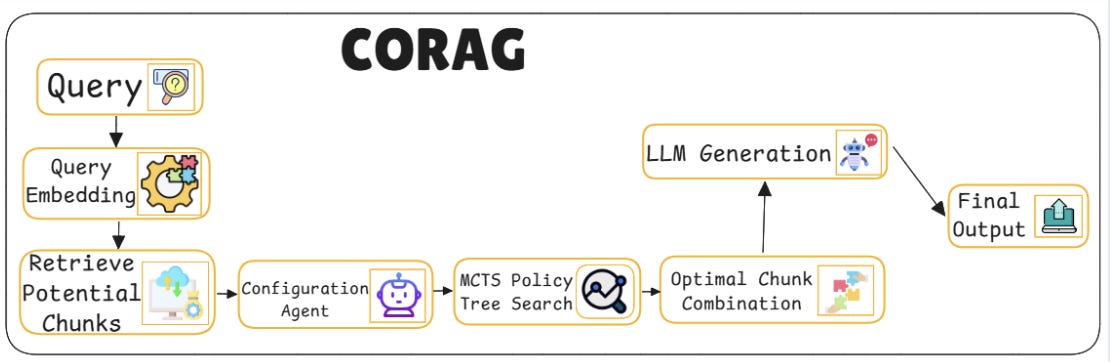
Key components:
Retrieval cost estimator: Before retrieving, the model estimates how “expensive” the operation might be based on token count, latency, or embedding calls and uses this to guide decision-making.
Budget-Aware retriever: The retriever isn’t just aiming for relevance it also tries to stay within the defined cost cap. It picks fewer but more relevant chunks, optimizing quality per token.
Dynamic trade-off mechanism: CORAG balances cost and utility on the fly. If a high-quality chunk is too expensive, it might substitute a slightly less ideal but cheaper one to stay within limits.
Early termination logic: If the budget is nearly spent and the generator has enough to go on, CORAG halts further retrieval to preserve resources, finishing the task efficiently.
19. EACO-RAG – Evidence-Aware Chunk Ordering
EACO-RAG doesn’t just retrieve the right chunks it figures out how to arrange them so the generator sees the strongest evidence first. The idea is simple: order matters.
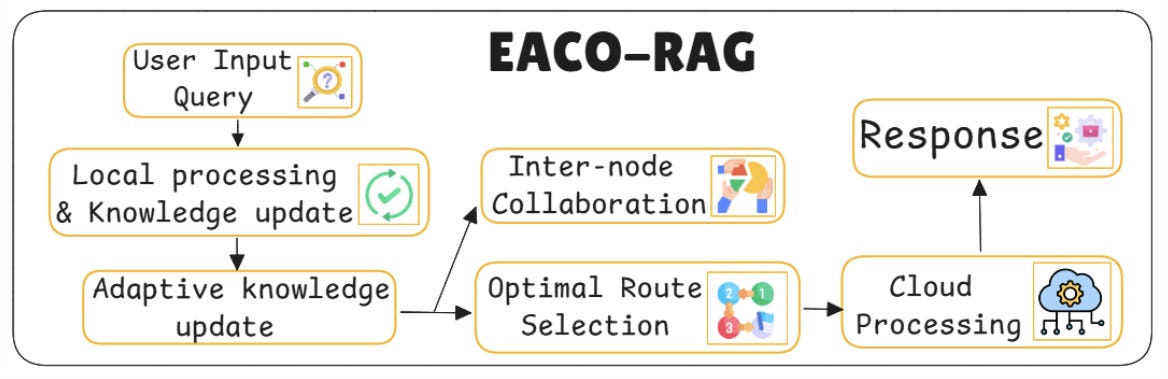
Key components:
Chunk relevance scoring: Retrieved chunks are not treated equally. EACO ranks them based on how well they match the query intent, often using cross-encoders or learned relevance models.
Evidence flow modeling: The architecture learns how evidence should build over time starting with stronger claims or definitions, then moving to support and elaboration.
Ordered context construction: The final input context isn’t randomly concatenated it’s structured like a mini-article. Important facts come first, supporting details follow.
Position-Aware attention bias: The generator is trained to weigh early chunks more heavily. Positional encoding tweaks ensure that the strongest evidence influences generation the most.
20. RULE RAG – Rule-Guided Retrieval-Augmented Generation
RULE RAG follows custom logic. Instead of pure neural decision-making, it blends retrieval with human-crafted rules or symbolic logic, giving more control over how and what it retrieves.
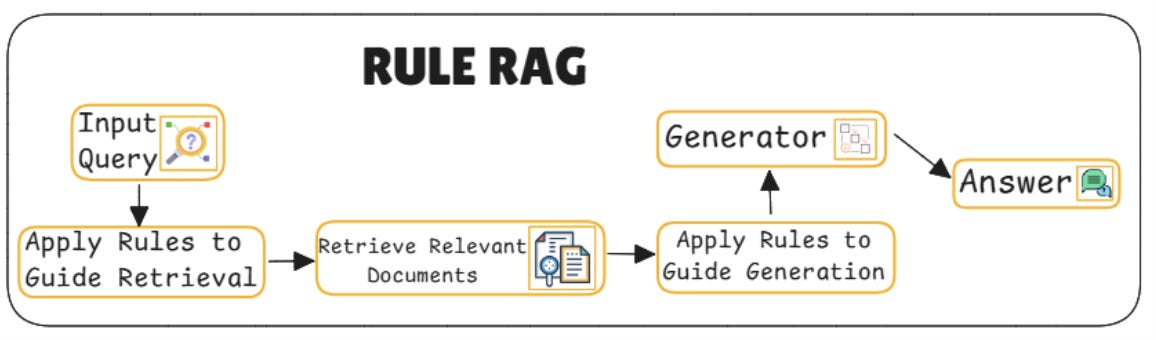
Key components:
Rule parser engine: A logic module parses if-then rules or domain constraints e.g., “If the query is legal-related, only retrieve from legal databases.”
Retriever routing layer: Based on parsed rules, the system decides which retrievers or sources to use. It can even blend them depending on specific rule outcomes.
Context filtering module: After retrieval, chunks that don’t satisfy the rules (e.g., wrong topic, outdated data) are filtered out before generation.
Rule-Aware generator prompting: Prompts are augmented with metadata or in-line signals derived from the applied rules to make the output more aligned and reliable.
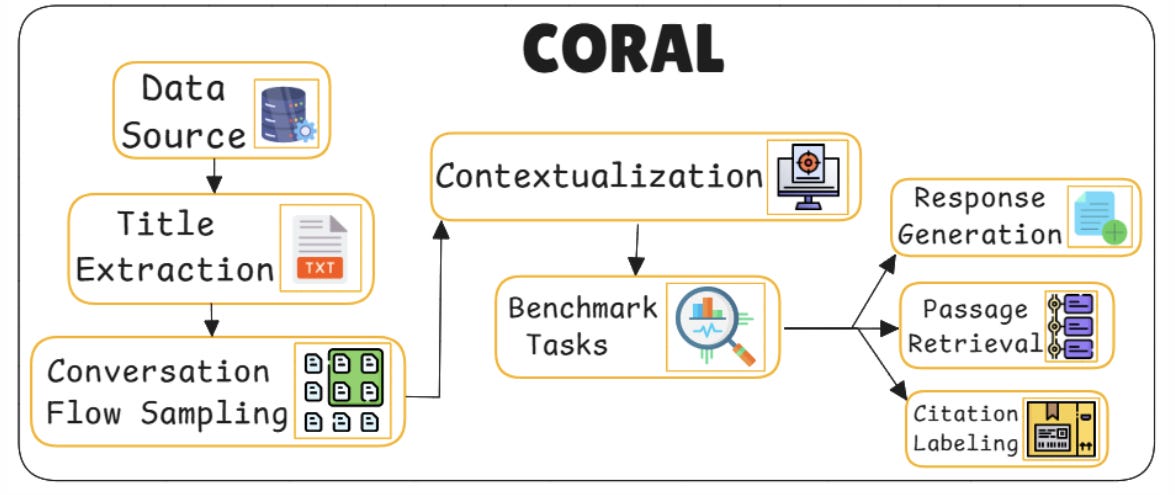
21. Conversational RAG
This one’s tailored for chat. Conversational RAG doesn’t treat every question as isolated it pulls in dialogue history, user behavior, and multi-turn memory to make responses contextually rich.
Key components:
Dialogue-Aware retriever: Instead of using just the latest user input, it retrieves using a mix of previous turns, intentions, and user profile info to form a more grounded query.
Turn-Level memory encoder: A module encodes each conversational turn separately and maintains long-range memory for previous questions, answers, or corrections.
Context stitching layer: Retrieved chunks from different dialogue turns are merged and aligned to avoid redundancy while preserving relevance.
Response coherence module: Generation includes checks for tone, consistency, and continuity so it sounds like one flowing conversation not disjointed facts.
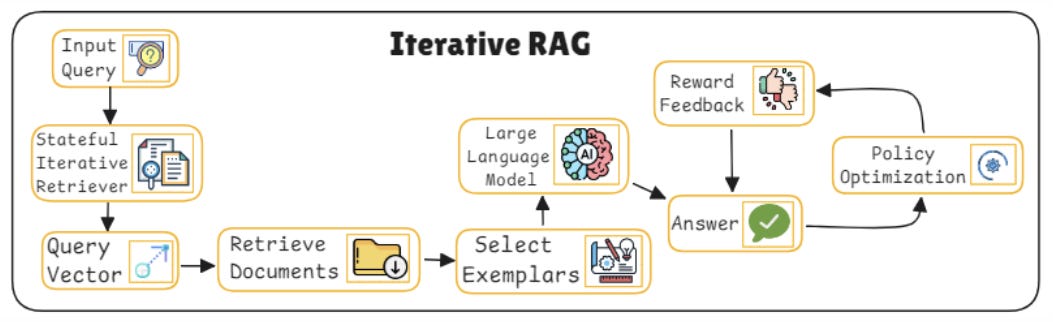
22. Iterative RAG
As the name implies, this model works in layers refining both retrieval and generation across multiple rounds. It’s ideal for complex queries that benefit from progressive reasoning.
Key components:
Round-Based retrieval engine: The retriever fetches context in stages starting with broad matches and then narrowing down based on earlier outputs and updated queries.
Intermediate generation steps: Instead of producing a final answer in one go, the model generates partial outputs, which are fed back to guide the next round of retrieval.
Refinement controller: A controller monitors the improvement of each round, deciding whether another iteration is needed or if the final output is ready.
Answer fusion layer: The final output is synthesized from multiple generations, selecting the best segments and integrating them into a cohesive response.
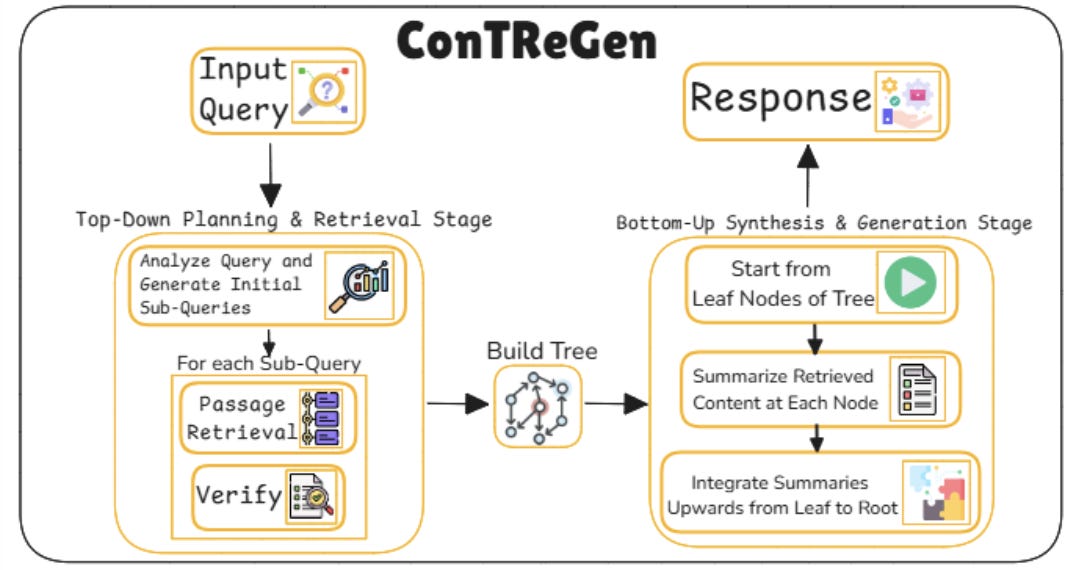
23. Context-Driven Tree-Structured Retrieval
This type organizes retrieval in a tree-like structure. Instead of retrieving flat documents, it breaks down the question, explores different paths, and builds a hierarchy of knowledge.
Key components:
Query tree constructor: A semantic parser breaks the main query into sub-queries, forming nodes of a tree that represent different aspects of the topic.
Hierarchical retriever: For each node in the tree, the retriever pulls context independently. This ensures comprehensive coverage of subtopics.
Tree encoder module: Retrieved sub-contexts are encoded in a tree-structured manner, preserving relationships across different query branches.
Aggregation & reasoning layer: Generation is performed after aggregating and reasoning across the full tree, stitching answers into one coherent, multi-faceted output.
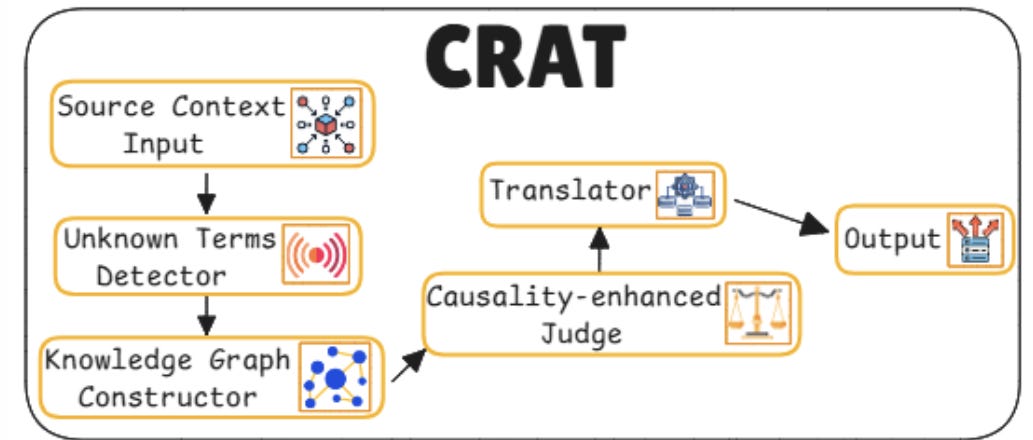
24. Causality-Enhanced Reflective and Retrieval-Augmented Translation (C-RRAT)
This one’s a mouthful, but the goal is powerful: bring retrieval into machine translation especially for causal or reflective reasoning tasks.
Key components:
Cross-Lingual retriever: During translation, the model retrieves facts in the source or target language to ground the output in external knowledge.
Causal graph encoder: Retrieved facts are structured into a causal graph, helping the model reason about dependencies or cause-effect relations across sentences.
Reflective decoder module: The decoder not only translates but reflects re-evaluating its own output in light of retrieved evidence, often adjusting phrasing for factual correctness.
Alignment verifier: A post-check mechanism ensures that the translated output remains faithful to both the source meaning and the retrieved causal structure.
25. Graph RAG
Graph RAG moves away from raw text chunks and into structured knowledge. It retrieves nodes and edges from a graph like a knowledge base and weaves that into its generation.
Key components:
Graph-Based retriever: Instead of text, the model retrieves relevant nodes, relations, and subgraphs using graph search or embedding similarity.
Subgraph constructor: Retrieved elements are structured into a local subgraph focused on the user query. This graph becomes the knowledge context for generation.
Graph encoder module: The subgraph is encoded using techniques like GNNs or relational attention, capturing not just entities but how they connect.
Graph-Aware generator: The generator integrates encoded graph context and leverages the structure for producing fact-rich, relation-aware answers.
Conclusion
As we wrap up this series on the 25 types of RAG architectures, one thing stands out: retrieval is no longer a static step it’s adaptive, iterative, and often intelligent. Whether you're building conversational agents, knowledge-rich assistants, or cost-aware enterprise models, there's a RAG type for that. And the next time someone says “RAG is just retrieval + generation,” you’ll know there’s a whole architecture jungle behind that simple sentence.

Until next time,
Stay curious, stay innovative and subscribe to us to get more such informative newsletters.
Read more of WTF in Tech newsletters:
Great series!