


Want to Build an LLM System? : Here’s the Blueprint I Wish I Had
Designing LLM Systems: A Practical Guide from Playground to Production.

Ever tried assembling IKEA furniture without the manual? That’s how designing an LLM system feels without a plan. I’ve been there wide-eyed, excited, and completely overwhelmed by the architecture diagrams floating around the internet. So I sat down and mapped it all out. In today’s edition of Where’s The Future in Tech you will learn how to map it too. Think of it as your LLM system design field guide minus the jargon overdose.

What You’ll Learn in This Guide
This isn’t just about hooking up an LLM to an input box. We’ll go deep into the system design mindset needed to build scalable, production-grade AI applications. Here's what's inside:
What is an LLM System, Really?
Core Components.
Hosting & Scaling.
Retrieval-Augmented Generation (RAG) – Worth the Hype?
Guardrails, Monitoring, and Safety Nets.
From Prototype to Production.
Section 1: What is an LLM System, Really?
Now, if the LLM is just the brain, then a real intelligent system is the whole person the one that remembers things, makes decisions, checks its work, and adapts to context. To build that, you need to surround the model with critical supporting systems.
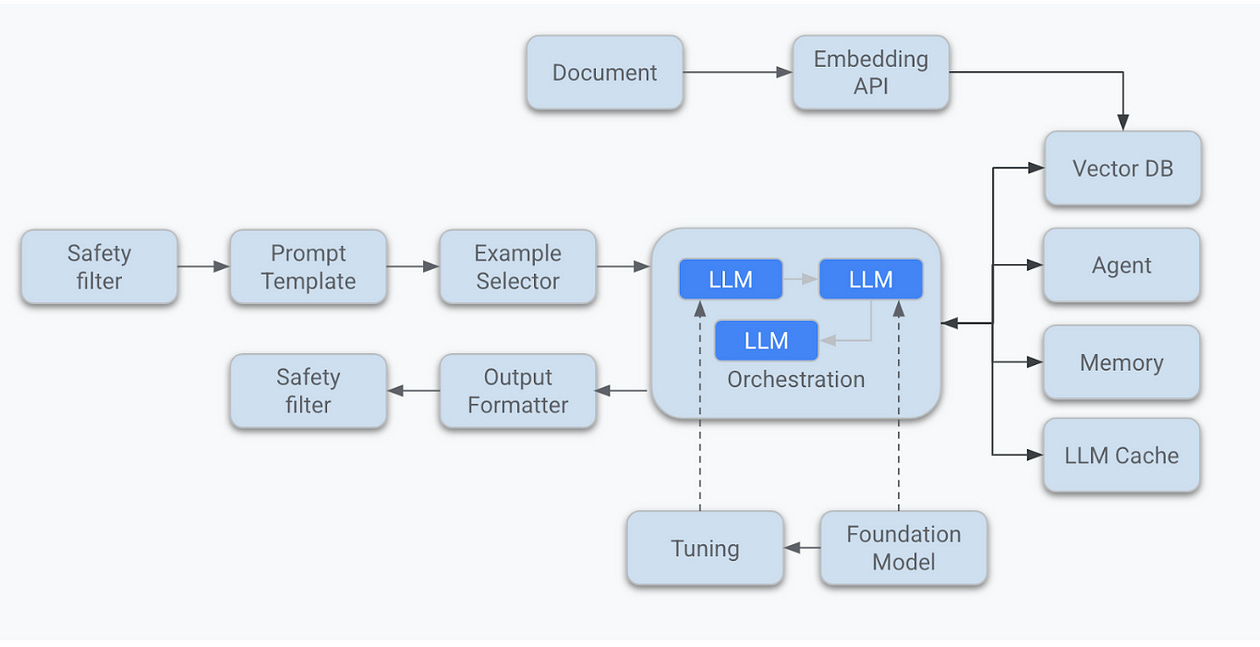
Let’s unpack each one:
Retrievers: Large Language Models are trained on vast corpora, but they’re not search engines. They can’t access real-time or domain-specific data unless you explicitly give it to them. That’s where retrievers come in. Retrievers use semantic search (typically via vector databases like Pinecone, Weaviate, FAISS, or Qdrant) to fetch relevant information from your own documents, wikis, databases, or APIs. This information is then injected into the prompt before sending it to the LLM. Think of it as giving your model a mini research assistant one that looks things up in your custom knowledge base before the model speaks.
Memory modules: Most LLMs operate statelessly by default they don’t “remember” what happened five minutes ago. But users expect a sense of continuity. They want the system to remember their name, their goals, their previous questions, or what was said earlier in the session.
There are two main types:
Short-term memory: Stores recent interactions (a few turns of dialogue). Often managed via context windows or caching.
Long-term memory: Stores persistent facts about users, conversations, preferences, or work sessions. This might live in a database, or be summarized into vector embeddings and retrieved when needed.
Evaluators: The LLM will confidently generate content even when it’s wrong, toxic, or irrelevant. You can’t just trust the output blindly, especially in production. Enter evaluators: these are subsystems (often themselves LLMs or classifiers) that check whether a response meets your quality bar. Evaluators can be used:
Pre-response, to filter prompt inputs or retrieved documents.
Post-response, to vet or re-rank outputs.
In A/B testing pipelines to compare candidate generations.
Orchestrators: The LLM can do many things summarize, generate code, search, plan, use tools. But who decides what it should do when? That’s the job of the orchestrator. The orchestrator is like a conductor in an AI orchestra.
This logic layer can be implemented using:
Finite state machines (for simple flows),
Function-calling APIs (like OpenAI’s tool use),
Planning agents (like LangGraph or ReAct),
Orchestration engines (like LangChain, Haystack, or Dust).
Routers: Routers are the traffic controllers of your system. They inspect the user input and decide: Routing helps you:
Optimize latency and cost (don’t overpay for simple tasks),
Improve quality (use stronger models when necessary),
Avoid failure (fallback to other models/tools when one fails).
Some systems use keyword-based routing, others use classifiers or even LLMs themselves to choose the right path. In short, the router ensures that each user query gets the right treatment like a triage nurse deciding which doctor you need to see.
Monitoring tools: Imagine deploying an LLM system with thousands of users and having no idea if it’s hallucinating, breaking, or just underperforming. Scary, right? That’s why monitoring is not optional.
Some monitoring can be manual (logs, dashboards), but many teams now use observability platforms like Langfuse, Helicone, TruLens, Phoenix, and OpenAI’s own usage dashboards.
Section 2: Core Components – The Heart of Any LLM System

Large Language Models might be the brain behind everything, but it takes a well-designed system around that brain to turn raw intelligence into a useful, reliable product. Let’s unpack the foundational components that transform a plain LLM into a powerful, structured, and production-ready system.
1. The LLM: At the center is the model itself. Think of it as a hyper-intelligent text predictor it doesn’t know facts; it knows patterns in data. It predicts the next token given a prompt, based on patterns it learned during training. Things to consider:
Architecture type (decoder-only vs encoder-decoder)
Context length (e.g., 4k vs 128k tokens)
Latency, cost, and fine-tuning capability
2. Prompting layer: Prompts are the actual input messages you craft to guide the model’s behavior. But this isn’t just manual prompting anymore modern LLM systems use smart templating, dynamic instruction crafting, and few-shot examples. It encodes user queries, tools, documents, memory, and goals into a structured format the LLM understands. It includes:
System prompts (to control tone and behavior)
User input injection
Retrieved document inclusion (from RAG)
3. Retriever: Your LLM was trained months ago and can’t magically learn your latest company policy or fetch yesterday’s news. That’s where retrieval comes in, it finds and injects relevant documents or context into the prompt from a vector database or search engine. How it works:
Text is chunked and embedded using an encoder (like text-embedding-ada-002)
Embeddings are stored in a vector DB (e.g., FAISS, Weaviate, Pinecone)
At query time, the system retrieves semantically similar chunks
Retrieved chunks are added to the prompt
4. Memory & state: While retrieval helps with factual grounding, memory helps with user continuity. Your system should be able to say, “As we discussed earlier...” without sounding like a broken record. It creates personalization, persistence, and trust over time.
Short-term memory = windowed message history
Long-term memory = embedded and summarized user data
Structured memory = key-value user state stored in a DB
5. Tool use & Function calling: LLM that only generates text is like an assistant who talks a lot but doesn’t do anything. Tool use allows the model to act run calculations, call APIs, search the web, query a database, and more. How it works:
The model receives a prompt describing a function or tool it can use.
It outputs a structured JSON call (e.g.,{ “function_name”: ..., “arguments”: {...}})
Your backend parses this, calls the tool, and feeds the result back to the model.
Section 4: Hosting & Scaling – Where Your LLM System Comes to Life
Once your LLM system is built, it's not enough to just get it running. You need to host it somewhere, ensure it can handle real-world usage, and gracefully scale as demand grows. Hosting and scaling are where ideas meet infrastructure and where many LLM projects go from prototype to production-ready.

Hosting:
Cloud APIs vs. Self-Hosting: There are two broad paths for hosting your model leveraging pre-hosted APIs (like OpenAI, Claude) or setting up your own infrastructure to host open models (like LLaMA, Mistral).
Pre-hosted APIs are easy to start with. You simply call an endpoint and get a response, no servers to manage, no DevOps overhead. It's the fastest way to ship a product. But you’re at the mercy of token pricing, rate limits, and black-box behavior.
Self-hosting gives you full control. You can finetune the model, reduce latency, keep data private, and optimize costs over time. But it's an engineering commitment. You'll need to provision GPUs, set up inference servers like vLLM or TGI, and manage load balancing and uptime.
Use API hosting for quick iterations and MVPs.
Use self-hosting when control, cost, or customization are priorities.
Scaling: Scaling isn’t just about handling more users it’s about handling them efficiently. A performant LLM system scales both technically and economically. Cold starts are a common bottleneck in self-hosted setups. Some models take several seconds just to load into memory. Tools like vLLM optimize for this by keeping model weights warm and efficiently managing GPU memory.
Concurrency is another challenge. One user is easy. Ten thousand? Not so much. You’ll need async APIs, message queues like Kafka, and load balancers to avoid collapse under pressure.
Then there’s memory management. Large prompts, long conversations, and high batch sizes can choke even powerful GPUs. You’ll need to optimize your prompt size, prune irrelevant context, or even run smaller distilled versions of your model.
Streaming is also critical for user experience. Instead of waiting five seconds for a full response, you can stream tokens as they’re generated. This is done using server-sent events or WebSockets especially useful in chatbot UIs.
API vs Self-Hosting: Choosing between API hosting and self-hosting isn’t just a technical decision it’s a product decision. Here’s a brief comparison for clarity:

Section 5: Retrieval-Augmented Generation (RAG) – Worth the Hype?
Absolutely and here’s why it’s not just another buzzword. At its core, RAG augments the capabilities of Large Language Models by pairing them with an external retrieval system. This means the model doesn’t have to remember everything it just needs to know where to look.

Here’s how it works:
Retrieve: When a user asks a question, the system first fetches relevant documents from an external knowledge base (like a vector store).
Generate: The LLM then reads this retrieved context and uses it to generate a more accurate, grounded response.
Why it matters:
Reduced hallucination: The model’s responses are tied to real, verifiable sources instead of just its training data.
Up-to-date answers: You don’t need to retrain the model to keep it current just update the retrieval source.
Cost-effective: Smaller or cheaper models can now perform better simply by being better informed.
Section 6: Guardrails, Monitoring, and Safety Nets
Deploying an LLM without oversight is like handing the mic to an improv comic at a legal deposition something’s bound to go off-script. That’s where guardrails, monitoring, and safety nets come in. These systems don’t just keep the model in check they ensure it's reliable, secure, and accountable.
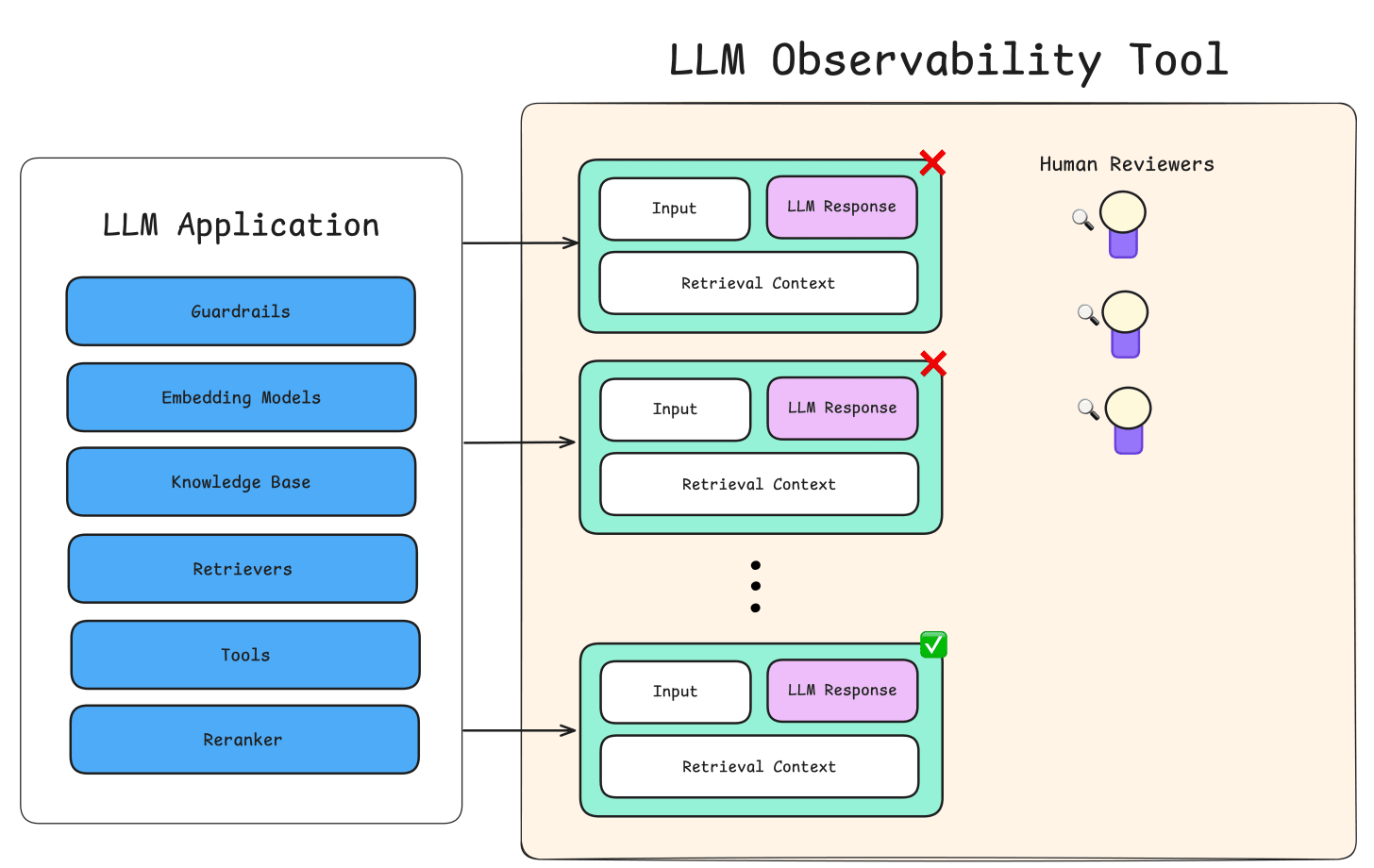
Guardrails: Guardrails are the rules of the road they restrict the model from veering into dangerous, irrelevant, or inappropriate territory. These can be hardcoded logic rules, policies enforced by an orchestrator, or even specialized pre/post-processing filters.
Examples:
Blocking responses about sensitive topics (e.g., self-harm, hate speech).
Preventing the model from giving medical or legal advice.
Monitoring: Think of monitoring as the flight recorder of your LLM system. It logs behavior, catches anomalies, and surfaces metrics so developers aren’t flying blind. What’s typically tracked:
Latency, token usage, and cost per query.
Flagged outputs (offensive, nonsensical, or unhelpful responses).
Tool/API calls made by the model, if applicable.
This is often integrated with tools like Prometheus, OpenTelemetry, or bespoke dashboards built for LLM observability.
Safety Nets: Even with guardrails and monitoring, failures are inevitable. Safety nets catch the fall and route things back on track gracefully. Typical safety strategies:
Fallback models: If the main model fails or takes too long, switch to a backup model or cached answer.
Human-in-the-loop (HITL): Escalate certain queries to a human reviewer, especially in enterprise or regulated contexts.
Response validation: Use classifiers or evaluators to automatically assess and reject low-confidence or toxic responses.


Section 7: From Prototype to Production
Everyone loves a good prototype. It’s fast, clever, and often built on duct tape and hope. You wire up a chat interface, toss in a few OpenAI API calls, maybe even sprinkle in some JSON mode. Voila it talks! But what feels like a leap forward in a hackathon doesn’t fly when real users show up with messy questions, regulatory concerns, and zero patience for downtime.

Generative AI Project Lifecycle
So what does it actually take to move an LLM system from a prototype to something that runs 24/7, handles scale, and doesn’t fall apart under pressure?
The Prototype phase: This is where you're experimenting testing out prompts, swapping models, sketching out basic workflows. The goal here is speed over structure. You’re often:
Building quick integrations (Flask apps, Streamlit dashboards, notebooks).
Manually testing prompts and outputs with handpicked examples.
Using little to no version control or testing.
And honestly, that's okay. This is where ideas are validated, and user feedback starts to shape the actual product. But it’s also the phase where things are most brittle no monitoring, no fallback paths, and probably no consideration of edge cases.
Laying the foundation: As soon as your prototype starts gaining traction users asking for more, outputs becoming business-critical the tone shifts. You can’t just rely on manual fixes or live-editing your prompts anymore. You need structure.
This is where you start building the system like it’s meant to live in the wild. You introduce versioning for models and prompts, write tests for your chain logic, and use CI/CD pipelines to push safe updates. Logging and telemetry become your eyes in the dark essential for tracking what the model is doing, where it’s failing, and how it's performing.
The Production phase: Production is where systems go from “working” to “working no matter what.” It’s not just about output quality anymore it’s about uptime, latency, monitoring, safety, and scalability. Models can hallucinate, APIs can fail, user behavior can spike unpredictably and your system has to survive all of it. At this point, you’re dealing with:
Load balancing and autoscaling for your backend and model endpoints.
Guardrails for filtering unsafe or unhelpful output.
Monitoring dashboards to track latency, cost, usage, and errors.
Fallbacks and retries to handle API timeouts or model failures.
Secure access and rate limiting to prevent abuse and comply with regulations.
Continuous feedback & iteration: Once deployed, your job isn’t done it's just different. You now focus on improving performance, optimizing latency and cost, and responding to real-world feedback. Tools like prompt versioning, dynamic model routing, and user feedback logging help you iterate intelligently.
Final Thoughts: Systems Over Scripts
Building with LLMs isn’t just about crafting clever prompts or choosing the "best" model it’s about engineering systems that are resilient, modular, and adaptable to real-world messiness.
From defining your system’s core components, to scaling it with the right infrastructure, embedding retrieval for relevance, enforcing safety, and moving from scrappy prototypes to production-grade deployments every layer matters. Each decision you make, from orchestrators to observability, contributes to the difference between an LLM that merely talks and one that truly performs.
In the end, great LLM applications don’t come from isolated components they emerge from thoughtful system design. And if you build it like a system, not just a script, it won’t just work it’ll last.
