
25 Types of RAG: Part 1
A Deep Dive into 8 RAG Architectures You Should Know!

RAG isn’t just a plug-and-play trick anymore. It’s an entire design philosophy and the architecture you choose can either supercharge your LLM app or bottleneck it into mediocrity.

In todays piece of Where’s The Future in Tech, I’ve broken down 8 of the most impactful RAG types I’ve come across from the no-nonsense Standard RAG to more experimental, dynamic forms like Self-RAG, Adaptive RAG, and the REFEED framework designed for vision-language harmony. Whether you’re building a research assistant, coding companion, or customer support bot, each type offers a unique architectural twist that solves specific bottlenecks if you know how to wire it all up correctly.
1. Standard RAG
The Standard Retrieval-Augmented Generation (RAG) model is the foundational design that laid the groundwork for how modern systems combine retrieval and generation. This design is often what we start with when experimenting with these types of architectures. Its simplicity and clarity make it a go-to for many early implementations.
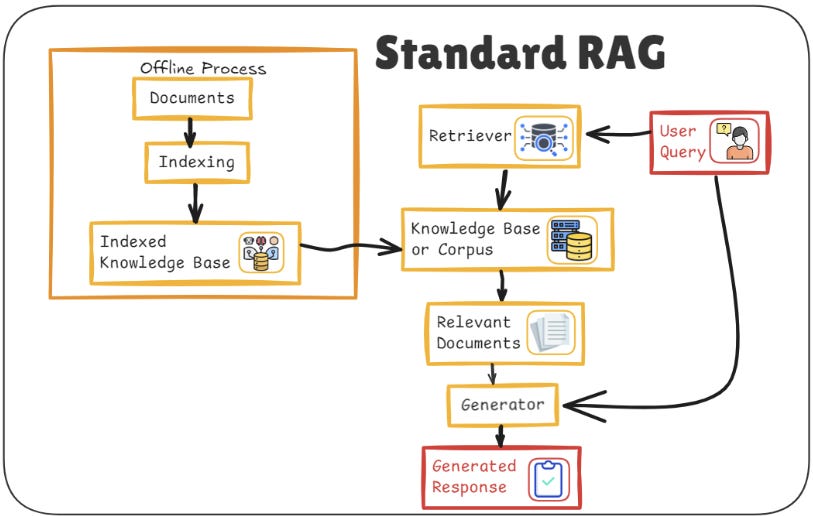
Let’s revisit the dual-tower setup. This is where we split the task into two major blocks the retriever and the generator.
How it all fits together:
The retriever is tasked with searching a knowledge base and retrieving the most relevant documents or passages. It does this by encoding both the query and all potential documents into dense vectors. By calculating vector similarities (using tools like FAISS or HNSW), the retriever selects documents that are likely to contain helpful information.
Once the retriever pulls these documents, the generator comes into play. It uses a transformer-based architecture (e.g., T5 or BART) to combine the query and the retrieved documents and generate a coherent response. This is where the magic happens. The generator synthesizes the information, providing a human-like, well-formed answer based on what it found.
What we get from this approach:
Modularity: The retriever and generator can be independently improved or swapped out. If you have a better retriever model, you can simply plug it in without needing to rework the generator.
Efficiency: By retrieving documents first, the generator can focus on what it does best: producing fluent, informative answers. It’s like giving the generator a cheat sheet only the most relevant documents are considered.
However, the limitation of this architecture is that the retriever and generator work in isolation. They don’t learn from each other directly, so any mistakes made by the retriever aren’t corrected by the generator, and vice versa. This can lead to inefficiencies in the way the system operates, especially when dealing with more complex queries or documents that require deeper analysis.
2. Corrective RAG (CRAG): Adding a Layer of Quality Control
Corrective RAG takes the standard architecture and adds a step that dramatically improves the quality of the output. As I mentioned earlier, CRAG introduces a relevance scorer after the retrieval phase to make sure the documents returned are the best possible matches. This additional step ensures that the documents feeding into the generator are highly relevant, improving both the quality and accuracy of the output.
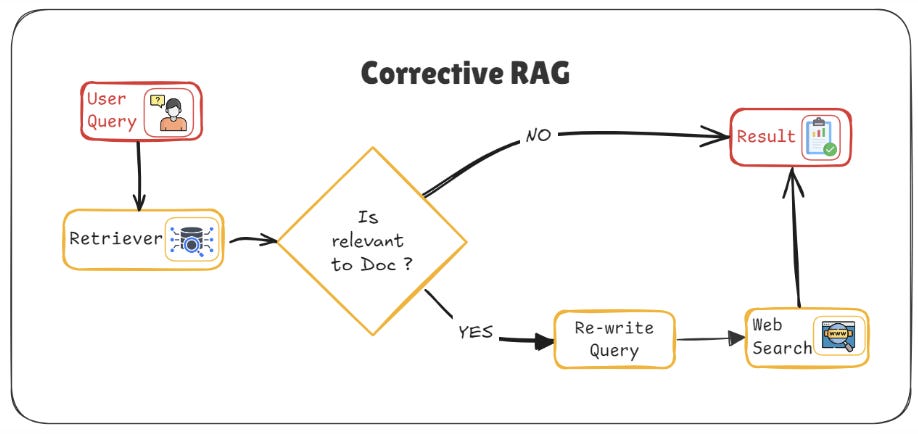
The key here is the cross-encoder. Instead of simply relying on dense retrieval (where documents are retrieved based on cosine similarity), CRAG uses a cross-encoder to compute the joint relevance of a query-document pair. This allows the model to evaluate documents more effectively, ensuring that only the most relevant ones are selected.
Architecture flow in CRAG:
First, the query is encoded, and documents are retrieved using a traditional dense retriever (just like in Standard RAG).
After this, each retrieved document undergoes an evaluation phase, where the cross-encoder evaluates the query-document pair. If the document is deemed irrelevant or of low quality, it is discarded.
Only the top-ranked documents make it through to the generator, ensuring that only high-quality, contextually relevant information is used for generating the response.
This additional step of evaluating documents in relation to the query provides a safeguard against irrelevant or noisy data, which is often the downfall of simpler retrieval systems. CRAG ultimately delivers more accurate and contextually aware responses, as the generator now works with a curated set of documents, giving it a cleaner, more reliable foundation to build upon.
3. Speculative RAG
Speculative RAG turns the standard RAG architecture on its head, introducing a clever approach where we generate multiple candidate responses and then refine them. Think of it like a brainstorming session where different possibilities are considered, and then the best one is selected after the fact.
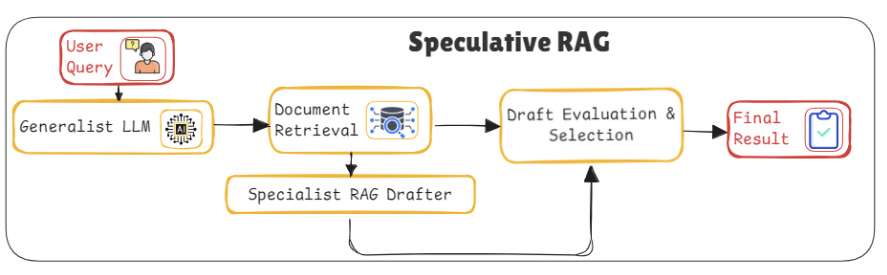
This method is driven by two main components:
A fast, lightweight draft generator that quickly produces multiple candidate responses based on the documents retrieved.
A stronger, more complex model that evaluates these candidates and selects the most suitable response. Sometimes, this stronger model may even synthesize the best parts of multiple responses to come up with a final, refined answer.
This architecture is designed to balance both speed and quality. By generating multiple options, speculative RAG reduces the risk of committing to a suboptimal answer. Instead, it gives the system wiggle room to explore different possibilities.
Here’s how the speculative architecture works:
After the documents are retrieved, the draft generator is triggered. This model is typically smaller and quicker, producing several possible answers that may range from very close to correct to potentially off-track.
These drafts are then passed to a larger model that evaluates the quality and coherence of the responses. This refining model ranks or even re-generates answers by blending the best elements of the drafts.
Finally, the model produces the final answer based on the strongest candidate.
Speculative RAG is an ideal approach when the output needs a bit of creativity or when there's a chance that the initial response might not be perfect. It gives the model a more exploratory phase, where multiple options can be tested and refined before delivering the final answer.
4. Fusion-in-Decoder (FiD)
Fusion-in-Decoder (FiD) is a bit like handling multiple ingredients in a recipe but making sure each one retains its identity until it’s time to mix them. Unlike traditional RAG models that fuse document vectors early in the pipeline, FiD keeps the documents separate until the very last step, during decoding.
In a traditional RAG architecture, documents are concatenated or merged into a single sequence before being passed to the generator. But in FiD, each document is processed individually and passed into a shared decoder that handles all the documents simultaneously.
Why is this better? Well, it allows the generator to attend to each document independently, preserving the unique context of each one. This is especially useful in scenarios where multi-hop reasoning is required i.e., when the answer lies in the intersection of information from different documents.
Key components of FiD:
Individual document processing: Each document retrieved gets its own individual embedding and remains separate during the encoding phase. This preserves the integrity of each document’s context.
Shared decoder: The shared decoder attends over all the document representations during the generation phase, allowing the model to draw information from multiple sources at once while retaining the context of each.
Why do we care about this? The biggest advantage here is that FiD doesn't flatten the documents by combining them prematurely. Instead, each piece of information maintains its own structure, allowing for better handling of more complex queries that require insights from multiple documents. It's an approach that focuses on contextual preservation, leading to more accurate and nuanced answers.
5. Agentic RAG
Agentic RAG represents a more advanced and dynamic approach. Imagine an AI that doesn’t just generate answers but actively makes decisions about what to search for next or how to adjust its behavior based on what it learns during the process. That's what an agent in RAG does.
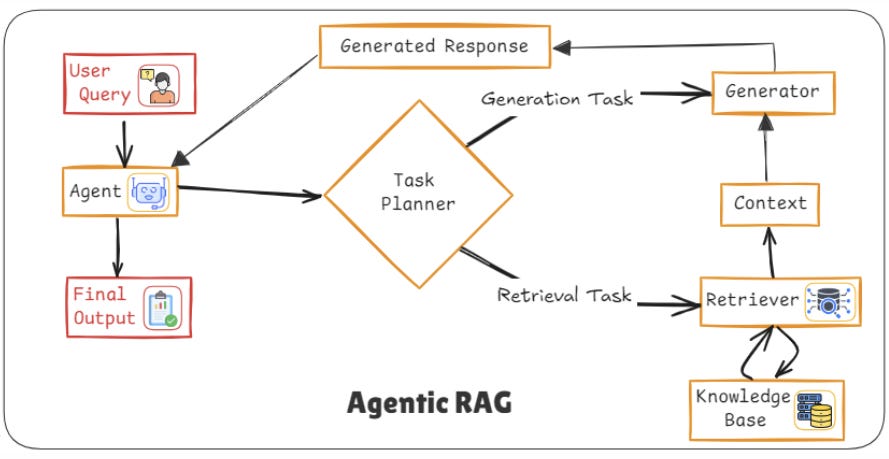
This architecture treats the retrieval and generation process as a loop of continuous improvement, where the model has autonomy to go beyond the initial query-document setup. It can initiate further searches, change its approach based on feedback, and even refine its own process as it learns.
Key components:
Retrieval process: Initially, the agent retrieves documents as usual.
Decision making: Instead of simply generating an answer from the retrieved documents, the agent decides what to do next. For example, it might recognize that the retrieved documents don’t contain enough information and request more.
Feedback loop: The agent continuously learns and improves based on feedback from previous queries, allowing it to become more efficient over time.
The beauty of this model is its self-improving nature. It's ideal for applications where an evolving, dynamic response is necessary think of virtual assistants or customer service bots that adapt and learn based on past interactions.
6. Self-RAG: The Self-Improving System
Self-RAG is a fascinating approach because it adds a feedback mechanism that allows the model to iteratively improve its retrieval process. Unlike traditional models, where the retriever and generator work independently, Self-RAG allows the generator to send feedback to the retriever, helping to refine the search process as the conversation or task progresses.
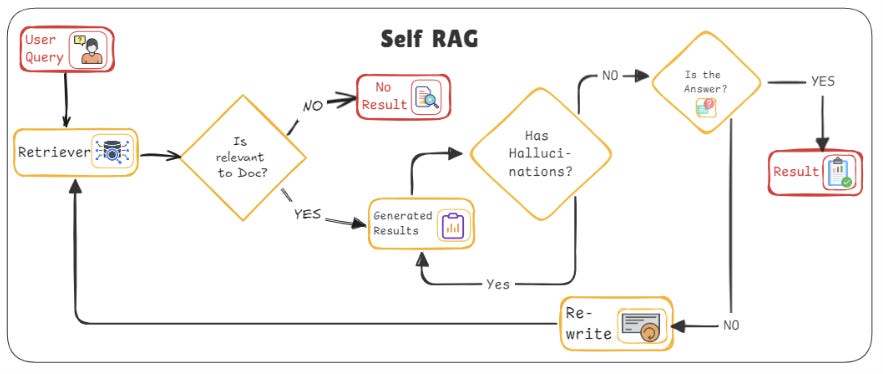
How it works:
Initial query & retrieval: The system begins by generating an initial response using the standard retrieval process. The retriever pulls documents from the knowledge base, and the generator creates a response.
Self-Correction and feedback: After the response is generated, the system checks whether the retrieved documents were truly sufficient to generate an accurate or informative answer. If the answer isn’t satisfactory, the system uses this information to refine its next round of retrieval, adjusting the weights and strategies for selecting documents. It essentially asks, “What went wrong?” and corrects itself by modifying its search approach for the next query.
Iterative improvement: The feedback loop doesn’t just happen once; it’s iterative. The more the system is used, the more intelligent and context-aware it becomes, adapting its search process based on past errors and successes.
Architectural Components in Detail:
Retriever with adaptation: The retriever is not static. It learns over time and can be dynamically adjusted based on feedback. In practice, this means the retriever gets better at picking out the right documents for complex, multi-step reasoning.
Generator with contextual understanding: The generator also improves its understanding of the query over time. As it gets feedback on what type of answers are more relevant, it fine-tunes its approach to generating responses.
Self-RAG’s most significant advantage is the ability to adapt to new types of queries or documents that may have initially been difficult to handle. Over time, it evolves to become increasingly efficient and effective, making it a powerful tool for long-term learning and adaptation in environments where the knowledge base is constantly changing or expanding.
7. Adaptive RAG: Personalization at Its Core
Adaptive RAG is built with a key idea: personalization. In many cases, a single generic model is not enough to handle the diverse needs of different users. This is especially true when the nature of queries varies significantly from one user to the next. That’s where Adaptive RAG comes into play. The system can personalize its retrieval and generation process based on user preferences, past interactions, and the specific context of the task at hand.
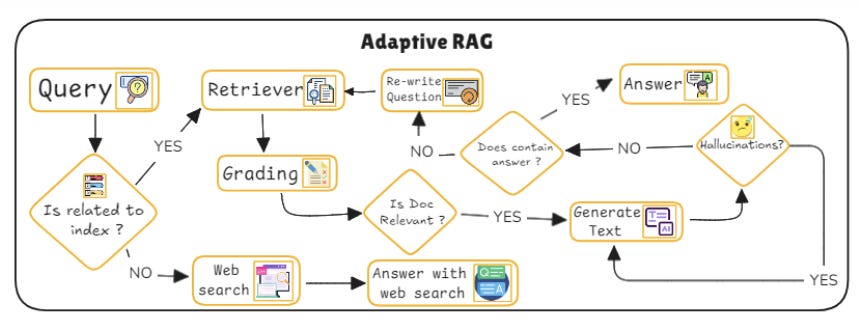
How Adaptive RAG works:
User profiling and Contextual awareness: Adaptive RAG starts by collecting data about the user’s preferences and previous interactions. For example, if a user frequently asks about a particular topic or prefers answers with certain stylistic traits, the system adjusts its retrieval and generation strategy to accommodate those preferences.
Dynamic retrieval strategy: Once the model understands the user’s preferences, it adapts the retrieval process. It may adjust the weight assigned to various documents based on the user’s historical choices or the context of the current query. This means that the model can retrieve documents that are more contextually relevant to the specific user, not just the query in isolation.
Personalized generation: The generator tailors the output not only based on the retrieved documents but also considering the user’s preferences for tone, complexity, or formality. If the user tends to prefer more technical responses, for example, the model will adjust its generation approach accordingly.
Architectural Considerations:
Dynamic document scoring: This includes not just relevance to the query, but also relevance to the user’s historical context or style preferences.
Adaptive model: The generator and retriever work in sync, learning over time from user interactions. By adapting based on usage patterns, Adaptive RAG ensures that the system’s responses are always improving in terms of both relevance and personalization.
The biggest advantage of Adaptive RAG is that it allows the system to evolve with each user. It’s highly flexible, capable of adjusting to new contexts without requiring complete retraining.
8. REFEED: A Refined Feedback Loop for Better Answers
REFEED (Retrieval Feedback-Enhanced Data) represents a more sophisticated mechanism of iterative refinement. Instead of simply retrieving documents and generating answers, REFEED involves an additional feedback step to refine the generated output before it is finalized.
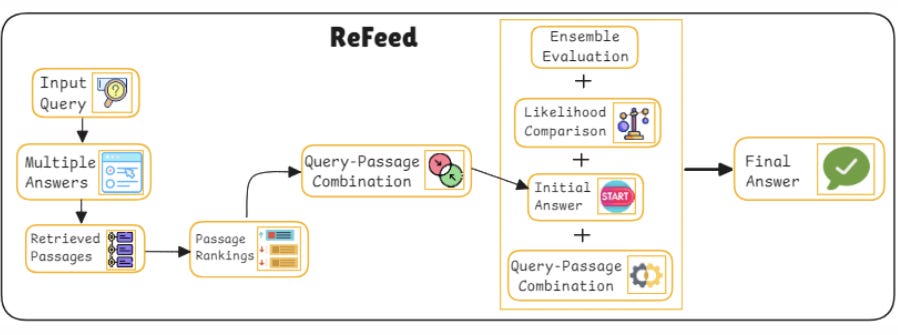
Here’s how REFEED enhances the process:
Initial retrieval & generation: The system first retrieves a set of documents based on the query and generates an initial response.
Evaluation and feedback: The system evaluates the answer for coherence, accuracy, and relevance. If the initial response lacks depth or contains errors, the model identifies weak points and uses feedback loops to retrieve more relevant documents or refine the current answer.
Refined response generation: The final step involves generating a more accurate response based on the additional feedback and refined documents.
Why REFEED works:
It mitigates the issues of misleading or superficial answers generated from irrelevant documents by revisiting the response and improving it iteratively.
This architecture is particularly valuable for complex queries where the first pass might not capture the full depth or precision needed.
REFEED is incredibly effective in settings where the accuracy of the generated response is critical, and it provides a more structured approach to refining and improving the model’s output.
Wrapping It All Up: Why the How of RAG Matters Just as Much as the What
After dissecting these eight architectures, one thing’s crystal clear there’s no universal blueprint for Retrieval-Augmented Generation. And honestly, that’s where the magic (and the challenge) lies.
Every architecture whether it’s Speculative RAG optimizing latency, Corrective RAG learning from its past mistakes, or Agentic RAG navigating tasks like a decision-making system reveals just how flexible the RAG framework has become. This isn’t about retrieval alone. It’s about engineering interoperability between the retriever, generator, feedback loops, memory components, and even agents.

Until next time,
Stay curious, stay innovative and subscribe to us to get more such informative newsletters
Very helpful
Simple and clear explanation. It was an enjoyable read without feeling overwhelmed.