

Let’s be honest. Every time we hear “RAG,” our brain briefly glitches between “Raggedy Ann”(the Annabelle doll) and “Retrieval-Augmented Generation.” If you're leaning toward the second, congrats you’re in the AI loop.
But wait, just when we wrapped our heads around good ol’ RAG, along comes Agentic RAG, wearing sunglasses and talking like it owns the place. So what’s the difference between these two? Is Agentic RAG just RAG on Red Bull? Or are we witnessing a deeper evolution in how machines reason?

In todays edition of Where’s The Future in Tech, let’s unpack this mystery.
First, What Is RAG?
Think of RAG as a way to let an LLM “cheat off a textbook” during a test. By default, LLMs can’t access new or private data. RAG solves this by letting them perform semantic search over a knowledge base and inject the most relevant results into the prompt, so the model can generate responses using fresh, grounded context.
Let’s say you ask:
“How does our internal OAuth flow differ from standard implementations?”
On its own, the LLM might hallucinate. But with RAG:
Your query is converted into an embedding vector.
A vector database (like Pinecone or FAISS) is searched for the most relevant documents.
These documents are fed into the model as context.
The LLM generates an answer using both its pre-trained knowledge and the retrieved info.
In practice, this works beautifully when:
You need accurate responses based on custom/internal content
Your data is constantly changing
Retraining the model is too slow or expensive
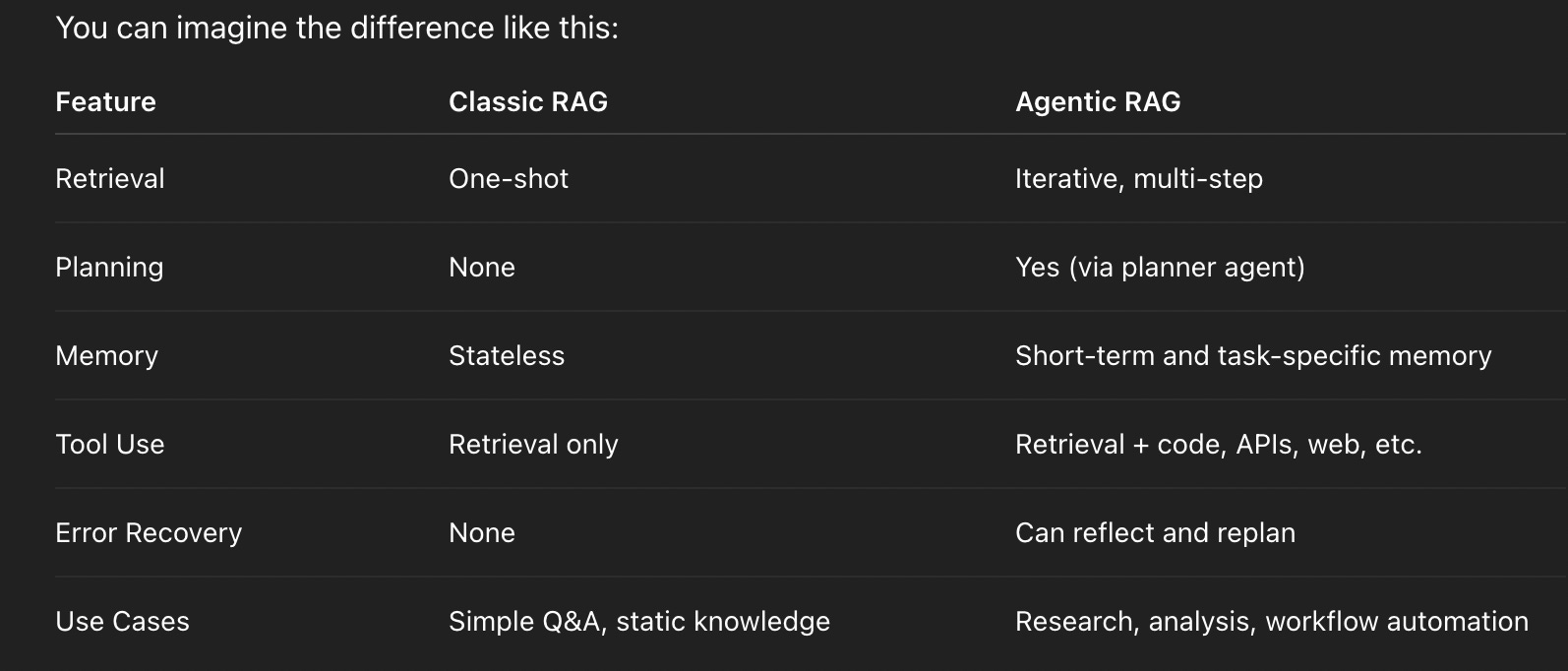
But here’s the catch: RAG is reactive. It retrieves once, answers once, and moves on. It doesn’t reflect. It doesn’t retry. It doesn’t ask, “Did I get this right?” This is where RAG begins to crack under complex questions, and why we started dreaming of something smarter.
Enter Agentic RAG: When Retrieval Learns to Think
If classic RAG is a diligent intern who fetches your documents, Agentic RAG is a junior researcher who reads them, challenges your assumptions, consults multiple sources, and iteratively builds a coherent analysis.
Instead of a one-and-done query, Agentic RAG systems:
Break down tasks into logical steps
Retrieve in stages, revising search based on earlier results
Use memory to carry knowledge between steps
Invoke tools like code execution, web search, or even APIs
Reflect on outputs and re-plan when needed
For example:
A user might ask:
“Compare the best-performing LLM fine-tuning strategies in the past 6 months and recommend one for our customer support use case.”
A classic RAG system might just retrieve a few blog posts and summarize them. An Agentic RAG system would:
Decompose the query into subtasks (e.g., “Find top strategies,” “Match them to use case,” “Highlight pros/cons”).
Execute targeted retrievals for each subtask.
Call tools or code to evaluate benchmarks if needed.
Synthesize the findings into a final, reasoned recommendation.
It behaves more like a thinking entity than a Q&A machine.
How They Differ Architecturally?
At a glance, both RAG and Agentic RAG might seem to do the same thing: they use retrieval to improve generation. But dig a little deeper, and you’ll see their architectural philosophies couldn’t be more different. Classic RAG is linear and reactive. It operates like a smart librarian you ask a question, it fetches a few relevant books (documents), and gives you a well-crafted summary. That’s it. No questions asked, no follow-up, no thinking beyond that single interaction.
Agentic RAG, on the other hand, is looped, modular, and adaptive. It's more like a research assistant with initiative. It doesn't just retrieve and summarize it plans, tests hypotheses, loops through evidence, calls in help from other tools, and only then composes a thoughtful, structured response. Let’s unpack this through a component-by-component comparison.
The Classic RAG Architecture
In classic RAG, the pipeline looks something like this:

Key components:
Encoder (Embedder): Converts the user’s question into a vector representation, enabling semantic search based on the meaning of the question rather than just keywords.
Retriever: Searches through a vector database to find the top-K most relevant documents that are related to the user's query.
LLM generator: Uses the user’s query along with the retrieved documents to generate a detailed, coherent response by synthesizing information from both sources.
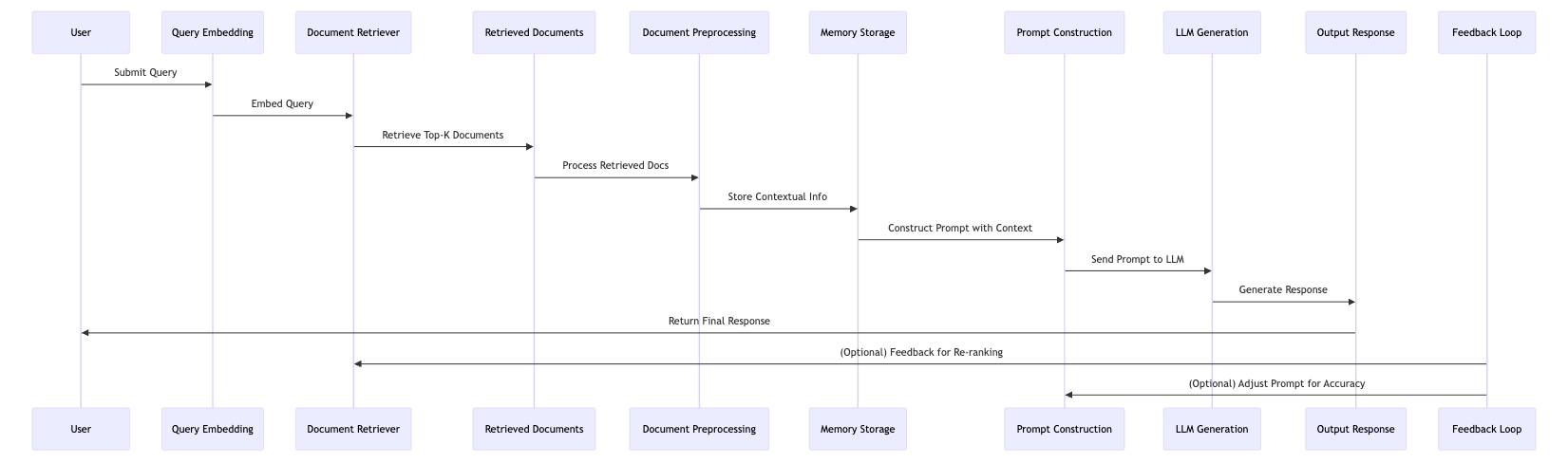
What it lacks:
Memory or iteration: RAG lacks the ability to remember past interactions or iterate on previous steps, making it a one-shot process with no learning or refinement.
Task decomposition: RAG does not break down complex tasks into smaller subtasks, which can make handling multi-step problems more difficult.
Decision-making across steps: RAG follows a linear process without the ability to adapt its decisions or strategies based on progress or feedback.
Ability to reflect or self-correct: RAG cannot assess its output or self-correct if the response is unsatisfactory; it generates answers without revisiting or improving them.
The Agentic RAG Architecture
Agentic RAG reimagines this pipeline as a multi-stage reasoning loop borrowing ideas from software agents and cognitive planning systems. The system is not answering a question; it's solving a problem. A high-level flow might look like this:

1. Planner / Task decomposer: Instead of jumping straight to answering, the system asks:
“What steps do I need to take to get a really good answer?”
This planner is usually an LLM (or LLM chain) that breaks the user’s input into subgoals or an execution plan. This decomposition makes it possible to handle ambiguity, nuance, and even multi-part queries.
2. Iterative retrieval + tool use: Agentic RAG doesn’t settle for one round of retrieval. Instead, it:
Runs multiple retrievals, each scoped to a specific subtask
Adjusts queries dynamically based on what it finds (e.g., “Search again, but focus on limitations”)
Chooses from a toolbox: RAG, web search, calculators, code execution, APIs, etc.
This turns retrieval into an active process, not a one-shot fetch.
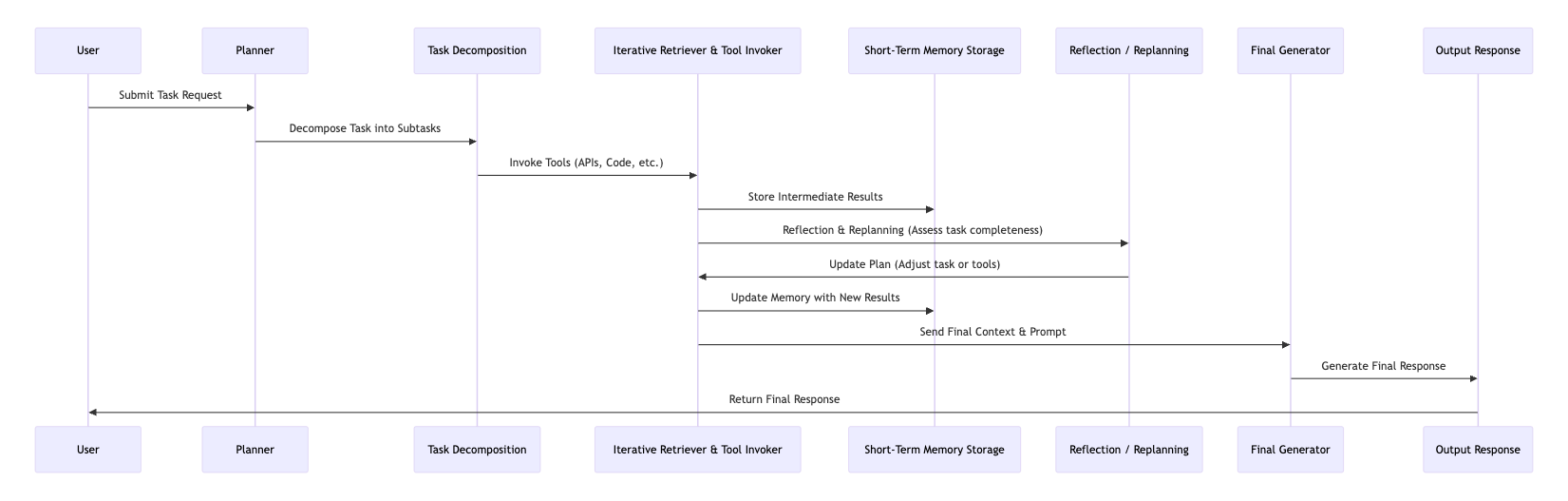
3. Short-Term memory (working memory): This acts like a notepad recording what’s been done, what’s been found, and what’s still pending. It can include:
Retrieved chunks and summaries
Intermediate conclusions
Plans for next steps
Reasoning traces (e.g., “We didn’t find enough data on X, let’s check Y”)
4. Reflection + replanning loop: Here’s where Agentic RAG really shines, after each major step, the system evaluates its progress.
Was this information relevant?
Did I retrieve enough evidence?
Do I need to refine my search or rephrase my query?
If something is off, it replans. This reflection-replanning loop makes the agent more robust, especially in open-ended or under-specified tasks.
5. Final synthesis / generator: After all the thinking, gathering and tool use is complete, the system composes the final output usually using a larger LLM or a specially prompted summarizer. But unlike classic RAG, this isn’t “one shot, one guess.” This means higher accuracy, richer reasoning, and crucially traceability. You can actually explain how the system reached its answer.
Why This Architectural Shift Matters
As LLMs move from chatbots to true assistants, they need more than a clever prompt and a search index. They need architecture that supports cognition:
The ability to pause, rethink, and retry
The ability to use tools and evaluate evidence
The ability to “see the forest and the trees” across steps
Agentic RAG brings that structure. It’s not just a better way to retrieve it’s a blueprint for giving AI systems the ability to reason in motion.
When to use RAG vs. Agentic RAG
If classic RAG and Agentic RAG were tools in a toolbox, RAG would be your precision screwdriver fast, reliable, and great for tight, specific jobs. Agentic RAG, on the other hand, is more like a multitool adaptable, layered, and better suited for complex assemblies where you might not even know what needs fixing yet. The key isn't choosing which is better, but knowing which is better for what.
When Classic RAG is your best bet
That’s where classic RAG shines: it’s fast, lightweight, and deadly accurate as long as your questions are direct and your knowledge base is strong. Use RAG when:
You’re building a Q&A bot over internal documents, product manuals, or knowledge bases.
The user’s question is fact-based or retrieval-heavy, like “What is the refund policy for product X?”
You need fast responses with minimal latency or compute cost.
You’re handling large volumes of queries and can’t afford the overhead of planning or tool orchestration.
When Agentic RAG is the Smarter Move
Let’s say the user query isn’t a question it’s a problem.
“Summarize the biggest regulatory risks in our last 20 quarterly reports and suggest mitigation strategies.”
That’s a task that requires context awareness, judgment, and the ability to synthesize across multiple documents, possibly even with domain-specific knowledge baked in.
This is Agentic RAG territory. It thrives when:
The query is ambiguous, multi-layered, or strategic.
The system must plan its approach, not just respond.
You’re building tools like:
Autonomous research assistants
Competitive analysis bots
Customer support triage agents
The system might benefit from using multiple tools, like:
RAG for context
Code interpreters for analysis
Web search for fresh data
Agentic RAG is especially powerful when the task unfolds in multiple stages like gathering context, checking for contradictions, filling in gaps, and then synthesizing the result. What makes it so compelling is that it behaves more like a teammate than a tool. It doesn't just retrieve it reasons. It doesn’t just repeat it reflects.
Tools to Build Agentic RAG Systems
If you're interested in actually implementing this, here are a few frameworks that support agentic behavior with RAG built-in:
LangGraph – Graph-based execution of LLM agents with memory and tool orchestration
CrewAI – Team-of-agents framework with planning, delegation, and long-form execution
DSPy – LLM programming framework for defining, optimizing, and executing agent workflows
Autogen (Microsoft) – Multi-agent coordination with chat-style agents and tools
Final Thoughts
We started with models that needed grounding. RAG gave them the power to reference the outside world. But now, with Agentic RAG, we’re handing them agency, the ability to take goals, make plans, reflect, adapt, and truly collaborate. This is where things get exciting. We’re not just building smarter chatbots we’re laying the foundation for AI coworkers, co-pilots, and eventually, creative partners. Agentic RAG doesn’t just give answers. It works problems, it handles ambiguity, it thinks forward.

Until next time, stay curious and keep learning!
Read more of WTF in Tech newsletter:
Really insightful article! What do you think is the best Python tool to start building Agentic RAGs? 🤔