
Building Multimodal Embeddings: A Step-by-Step Guide
Learn how to create AI models that seamlessly understand text, images, and more.

You see a blurry photo of a golden retriever mid-jump, tail wagging, tongue out. A second later, someone says, “Looks like someone’s happy to see you!”. Your brain doesn’t struggle. It weaves all of it sight, sound, and context into a single coherent moment. That’s the human edge: multimodal understanding.
Now here’s the wild part: machines are starting to learn that trick too. And the key?
Not bigger models. Not more GPUs. Just better embeddings. More specifically: multimodal embeddings a mind-bending innovation that allows AI to represent images, audio, text, and even video in the same vector space. Meaning? AI can now “feel” relationships across senses.
It can:
Match a meme to a vibe.
Find an image based on a sentence.
Describe a video without ever seeing it before.
This isn’t AI that understands words or pictures. It’s AI that understands moments.

In this edition of Where’s The Future in Tech, we’ll go deep into how it all works. By the end, you’ll not only understand how machines are learning to think across senses you’ll be ready to train one.
The Problem with Unimodal AI
Unimodal models can’t:
Look at an image and answer a question about it.
Watch a video and summarize what happened.
Hear a command and execute a vision-based task (like “Find the blue bottle on the table”).
Real-world intelligence is multimodal. Context isn't just in text. It's in tone, timing, visual cues, spatial relationships, semantic overlaps. If we want machines to operate in the real world not just websites and spreadsheets we need to bridge these modalities. And that’s exactly where multimodal learning and shared embeddings come in. AI has been impressive but oddly one-dimensional.
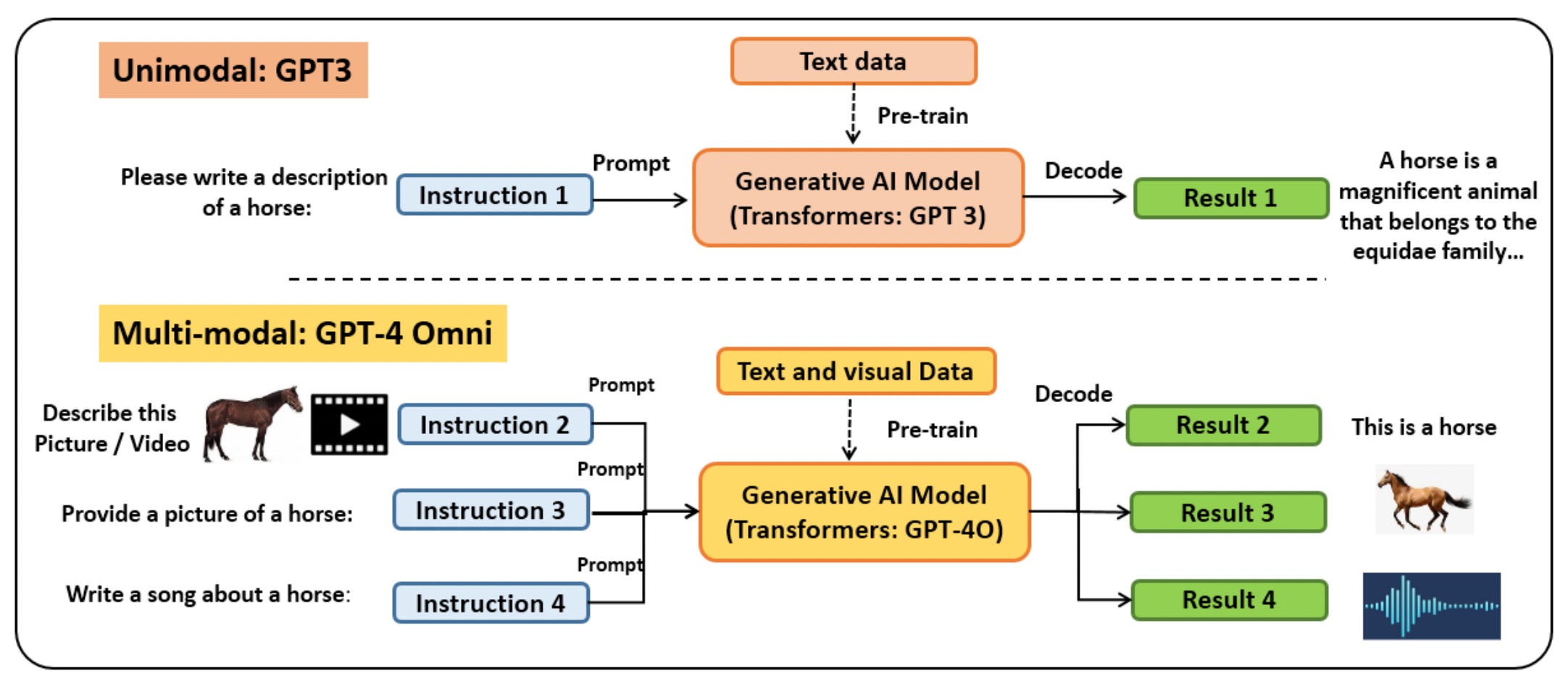
For years, we’ve built powerful models in isolated silos:
NLP gave us chatbots that can draft essays, code, and write love poems (GPT, BERT).
Computer vision gave us facial recognition, object detection, and deepfake generators (ResNet, YOLO, ViT).
But here’s the catch: Each of these models only understands the world through a single lens. That’s like teaching someone to read, but never showing them a picture book. It works… kind of. But it’s incomplete.
What Are Embeddings?
In machine learning, particularly in natural language processing and multimodal systems, embeddings refer to the numerical vector representations of discrete input data such as words, sentences, images, audio, or even video projected into a continuous vector space. These vectors are learned such that semantic or contextual similarity in the input domain corresponds to spatial proximity in the embedding space. An embedding is a mapping function:
f:X → R^dWhere:
X the input space (e.g., tokens, pixels, mel-spectrograms)
d is the dimensionality of the embedding space (typically 128 to 4096)
f(x)∈R^d is the vector representation of the input x
In practice, these vectors are produced by the final (or intermediate) layers of deep neural networks trained on large-scale data. The objective is often to preserve semantic relationships, meaning that inputs with similar meaning, context, or function are represented by vectors that are closer together under a chosen distance metric, typically cosine similarity or Euclidean distance.

Example: Word embeddings
In NLP, word embeddings like Word2Vec, GloVe, and contextual ones like BERT or GPT transform tokens into vectors that encode:
Syntax (part of speech)
Semantics (meaning)
Context (nearby tokens)
For instance:
vec("king")−vec("man")+vec("woman")≈vec("queen")This arithmetic only makes sense because the embedding space has learned latent dimensions such as gender, royalty, or plurality.
Embedding Spaces as Conceptual Landscapes
A trained embedding space can be viewed as a high-dimensional manifold of meaning, where:
Clustering implies semantic grouping (e.g., all bird species near each other)
Vector directions correspond to latent attributes (e.g., pluralization, color, sentiment)
Cross-modal alignment places semantically similar inputs regardless of modality near each other

In a multimodal system like OpenAI’s CLIP:
The caption “a red sports car on a mountain road”
And the actual image of it
are embedded into the same vector space making zero-shot image classification and retrieval possible.
The Architecture Behind Multimodal Embeddings

1. Encoders: The role of encoders is to convert raw modality-specific input into dense, fixed-size vector representations. For text, this usually involves a transformer-based language model such as BERT, RoBERTa, or a variant of GPT, which tokenizes the input and produces contextualized representations. A [CLS] token, mean pooling, or a dedicated projection head is often used to extract a single vector from the sequence. For images, the encoder is typically a convolutional neural network (like ResNet) or a Vision Transformer (ViT), which takes in pixel arrays, processes them into patches or feature maps, and ultimately produces a compact embedding vector. Audio and video follow similar principles using specialized architectures like wav2vec or TimeSformer.
2. Embedding space: Once inputs are encoded, their embeddings are projected into a shared vector space typically a high-dimensional Euclidean or cosine space where semantic relationships are represented as geometric distances. This space is carefully shaped during training so that semantically similar inputs, regardless of modality, are mapped to nearby points. For example, the phrase “a dog playing fetch” and a corresponding image of that activity would be embedded close to each other in this space, even though one originates from textual tokens and the other from pixel data.

3. Contrastive loss:The learning signal that shapes this shared embedding space is typically a contrastive loss, with InfoNCE being one of the most widely used formulations. During training, the model is fed pairs of matching inputs (e.g., an image and its caption) along with many negative pairs (non-matching samples from the same batch). The loss function encourages the model to increase the similarity (usually cosine) between matching pairs while decreasing the similarity between mismatched ones. This objective not only pulls semantically aligned representations closer together but also helps the model distinguish nuanced differences across a large number of examples.
InfoNCE Loss (CLIP-style):
Given a batch of NNN image-text pairs:

Where:
sim(a,b) is cosine similarity: (a⋅b)/(∥a∥∥b∥)
τ is a learnable temperature parameter that scales similarity.
This trains the model to align matched pairs while maintaining separation from mismatches across the batch.
4. Fusion layers (Optional): While contrastive training focuses on aligning separate representations, some downstream tasks like visual question answering or multimodal reasoning require more direct interaction between modalities. This is where fusion layers come into play. Instead of keeping modalities separate until after encoding, fusion-based models allow information to flow between modalities during the encoding process. This is often achieved through cross-attention mechanisms, where, for instance, text tokens attend to visual feature maps, enabling the model to ground language in perception. Fusion Methods:
Early fusion: Concatenate raw inputs or tokens before encoding (e.g., image patches + tokenized text).
Late fusion: Encode each modality separately, then merge embeddings via attention or concatenation.
Cross-attention: One modality attends to the other e.g., text tokens attend to visual embeddings.
Examples:
ViLBERT / LXMERT: Use two-stream transformers with cross-modal attention.
GIT (Generative Image-to-Text): Vision encoder → text decoder (GPT-style) → caption generation.
5. Pre-training data: The quality and scale of the pre-training data used to learn multimodal embeddings are crucial to their generalization capabilities. These models typically require large-scale, naturally occurring pairs of data from different modalities such as image–caption pairs scraped from the web (e.g., LAION, Conceptual Captions), video–text pairs from instructional videos (e.g., HowTo100M), or audio–text annotations (e.g., AudioCaps). Importantly, these datasets don't need manual labeling, as alignment can often be inferred from surrounding context (e.g., alt-text or subtitles).
6. Example: CLIP by OpenAI: CLIP is one of the most well-known multimodal embedding models. It was trained on 400 million (image, text) pairs, scraped from the internet.
CLIP’s architecture:
Vision encoder: a modified ResNet or ViT
Text encoder: Transformer
Training objective: Contrastive loss across large batches
Beyond CLIP: The Expanding Multimodal Landscape
Multimodal embeddings have gone far beyond just text + images. Here are some state-of-the-art models and their modalities:

How to Build One (Yes, You Can)
If you’ve ever wondered whether you need a supercomputer and a billion-dollar dataset to build a multimodal model, the answer is: not necessarily. While models like CLIP or Flamingo are trained on massive infrastructure, the architecture itself is surprisingly replicable on a smaller scale with open datasets, smart batching, and a few tricks up your sleeve. Let’s walk through the core components and how to implement them yourself.
Step 1: Choose your modalities - Start by deciding which modalities you want to align. The classic setup is text + image, but you could just as easily work with text + audio, image + video, or even more exotic pairs like text + time-series data. Each additional modality adds complexity, so if this is your first run, stick to text and image the ecosystem is well-supported, and datasets are abundant.
Step 2: Pick your encoders (Or use pre-trained ones) - You need one encoder per modality. For text, you can use a pretrained transformer like DistilBERT, MiniLM, or even sentence-transformers from Hugging Face. These models are lightweight and deliver strong performance for sentence-level embeddings.
For images, try a pretrained ResNet-50 or ViT (Vision Transformer). Make sure each encoder produces a fixed-size output e.g., 512 or 768 dimensions. If they don’t match, you can add a projection head (a simple linear or MLP layer) to map both into a shared dimensionality.
Step 3: Prepare your paired dataset - You need a dataset of paired samples such as image-caption pairs. Great open datasets include:
Flickr30K (31K images with 5 captions each)
COCO Captions
LAION-400M subset (if you’re feeling ambitious)
Or scrape your own: HTML
altattributes + image links = DIY dataset.
Make sure to preprocess text (tokenization, truncation) and resize/normalize images (standard ImageNet pipeline works). Keep batch sizes modest (e.g., 32–64) to fit on a single GPU or even CPU.
Step 4: Define the contrastive loss - Once you have your embeddings, compute the cosine similarity between every text and image pair in a batch. Then apply InfoNCE loss, which encourages positive pairs to have higher similarity scores than all negatives in the same batch.
You’ll need two logits matrices:
One for image → text similarities
One for text → image similarities
Apply softmax to both, calculate cross-entropy loss for each, and take the mean. This dual loss is how CLIP gets bidirectional alignment.
Step 5: Train the model - Use a standard optimizer like AdamW, with learning rate warm-up and cosine decay. Training even a small model can take a few hours on a decent GPU (e.g., RTX 3060 or a Colab Pro session).
Key training tricks:
Normalize embeddings before computing similarity (L2 norm)
Use temperature scaling (learnable parameter τ in InfoNCE)
Shuffle batches frequently to improve negative sampling
Validate using recall@K: how often does the correct match appear in top-K results?
You can train for as little as 5–10 epochs to see promising results on small datasets.
Step 6: Evaluate & visualize the embedding space - Once trained, take a random image and find the most similar captions or vice versa. This is zero-shot retrieval in action. To visualize the learned embedding space, project your embeddings into 2D using t-SNE or UMAP. You should see semantically similar points clustering across modalities images of dogs close to the word “puppy,” pictures of planes hovering near “airport,” and so on.

Optional: Fine-tune or extend to fusion tasks - If you want to go beyond alignment into generation or reasoning, you’ll need to build on top of your embedding model with cross-attention layers, decoders, or fusion transformers. But even without that, a cleanly trained dual-encoder with contrastive loss unlocks powerful use cases like:
Multimodal search engines
Tagging and caption generation
Conclusion
Multimodal embeddings are transforming how machines understand and process data across text, images, audio, and more. By aligning these diverse data types into a shared space, these models enable applications like content retrieval, creative generation, and advanced reasoning tasks. The best part? You don’t need a massive budget or supercomputer to get started. With open-source tools, pre-trained models, and a bit of creativity, you can build your own multimodal system. It’s all about connecting data types and creating AI that truly understands context.

Until next time,
Stay curious, stay innovative and subscribe to us to get more such informative newsletters.
Wow thanks !!