


Qwen3: Alibaba’s new weapon in the Open-Source LLM Wars
Complete guide to understanding this powerful Open-Source LLM

Just when we thought the open-source LLM space couldn’t get more crowded, Alibaba’s Qwen3 kicked down the door and it didn’t come alone. It brought scale, multilingual mastery, function-calling finesse, and even a giant MoE-powered beast that quietly outperforms GPT-4.
But here's the twist: unlike some contenders that flash and fade, Qwen3 is open-weight, practically usable, and surgically engineered for real-world application not academic benchmarks alone.

In todays edition of Where’s The Future in Tech let’s dissect what makes Qwen3 stand out, why its MoE models are architecturally clever, and how it carves out a serious role in the modern LLM stack.
What Is Qwen3?

Qwen3 is Alibaba’s next-gen open-source large language model family that combines massive scale, multilingual fluency, and efficient sparse Mixture-of-Experts architecture to deliver powerful, flexible AI capable of handling everything from lightweight chatbots to complex reasoning with ultra-long context support. It is not your average large language model. It combines multiple advanced features that set it apart:
Multilingual foundation: Unlike many models that are English-centric, Qwen3 was trained with over 30 languages from day one. This means it understands cultural nuances, idioms, and syntax from across the globe, making it genuinely versatile for international applications.
Built-In structured output: Many models struggle to output consistent JSON, code snippets, or API calls without careful prompt engineering. Qwen3, however, is trained to generate these structured formats natively, reducing developer headaches and increasing reliability when integrating with software tools.
Sparsity through Mixture of Experts (MoE): Instead of activating every single parameter for every input (which wastes compute), Qwen3 uses MoE to selectively “turn on” only the experts needed for each task. This innovation allows the model to be massive without being prohibitively expensive or slow during inference.
Qwen3 models introduce a hybrid approach to problem-solving. They support two modes:
Thinking mode: In this mode, the model takes time to reason step by step before delivering the final answer. This is ideal for complex problems that require deeper thought.
Non-Thinking mode: Here, the model provides quick, near-instant responses, suitable for simpler questions where speed is more important than depth.

Qwen3-235B-A22B: The MoE Giant
At a glance, 235 billion parameters sounds massive and it is. But here’s the catch: only 22 billion of those parameters actually activate for each request.
Selective activation means efficiency: Imagine a team of 235 specialists where only the most relevant 22 are called upon for each problem. This selective approach slashes computation costs while retaining powerful problem-solving abilities.
Benchmark beater: Despite being “sparse” in activation, Qwen3-235B matches or outperforms GPT-4 on several difficult benchmarks, including math reasoning (GSM8K), general knowledge (MMLU), and code generation (HumanEval). This is a testament to how effective MoE can be at scale.
Currently closed weight, enterprise focused: Alibaba uses this model internally, powering enterprise copilots and cloud services. While it’s not openly available yet, its success shows MoE’s potential to revolutionize commercial AI deployments.
Qwen3-30B-A3B: Power Meets Practicality
If Qwen3-235B is the experimental supercar, the 30B-A3B is the reliable, high-performance sedan ready for the daily grind.
Efficient powerhouse: Activating only 3 billion parameters out of 30 billion per inference, this model balances strong reasoning capabilities with manageable compute requirements. It’s perfect for developers who need power but can’t afford massive infrastructure.
Handles massive context windows: With support for up to 128,000 tokens, it’s built for tasks requiring deep context retention think long documents, multi-turn conversations, or complex codebases.
Multilingual and structured outputs: Like its bigger sibling, the 30B-A3B shines at generating precise JSON, code, and tool calls while smoothly handling a wide range of languages, making it a versatile choice for global applications.
Accessible yet powerful: Compared to other open-source models in the 30B range, Qwen3-30B-A3B delivers a rare mix of top-tier performance and speed, all without demanding huge computational resources.

The Rest of the Qwen3 Family (0.5B – 72B)
Alibaba released dense models across a spectrum to support different workloads. Model profiles:
Qwen3-0.5B & 1.5B:
Ideal for edge inference, IoT, low-memory devices.
Surprisingly good for single-turn prompt-response interactions.
Qwen3-4B:
Strong fine-tuning candidate.
Fits on consumer-grade GPUs; useful for custom RAG bots and embedded LLMs.
Qwen3-7B & 14B:
Excellent out-of-the-box instruction following.
Qwen3-14B in particular rivals Mixtral in general chat.
Qwen3-72B:
Dense model think of it as a more open, long-context Claude.
Performance comparable to GPT-4 on many reasoning tasks.
Each model supports long context windows, multilingual capabilities, and open weights a huge win for fine-tuners and startups.
Which Qwen3 Model Should You Choose?

How Qwen3 Was Developed
The development of Qwen3 was a massive and meticulous effort to push AI capabilities further by expanding training data, refining training processes, and innovating model design.
Pretraining:
Compared to its predecessor Qwen2.5, Qwen3 was trained on nearly double the amount of data about 36 trillion tokens across 119 languages and dialects. This enormous dataset wasn’t just scraped from the web but also extracted from PDF-style documents using previous Qwen models, which helped improve the quality of the collected text. To boost the model’s skills in math and coding, synthetic data was generated with specialized versions of Qwen2.5, including textbooks, Q&A pairs, and code snippets.
The pretraining itself happened in three stages:
Stage 1: Training on 30 trillion tokens with a 4,000-token context length, laying down broad language skills and general knowledge.
Stage 2: The dataset was refined with more STEM, coding, and reasoning data, adding 5 trillion tokens to boost domain-specific knowledge.
Stage 3: Finally, high-quality long-context data was used to extend the model’s context window to 32,000 tokens essential for handling long documents and complex tasks.
Interestingly, Qwen3’s dense base models with fewer parameters matched or outperformed larger Qwen2.5 models in critical areas like STEM, coding, and reasoning, showing that smarter data and training trump raw size. Meanwhile, the sparse MoE models matched dense Qwen2.5 models’ performance using only 10% of the active parameters, dramatically cutting down training and inference costs.
Post-training: Sharpening Reasoning and Responsiveness
To create the hybrid model that can both reason deeply and respond quickly, Qwen3’s training continued with a sophisticated four-stage pipeline:
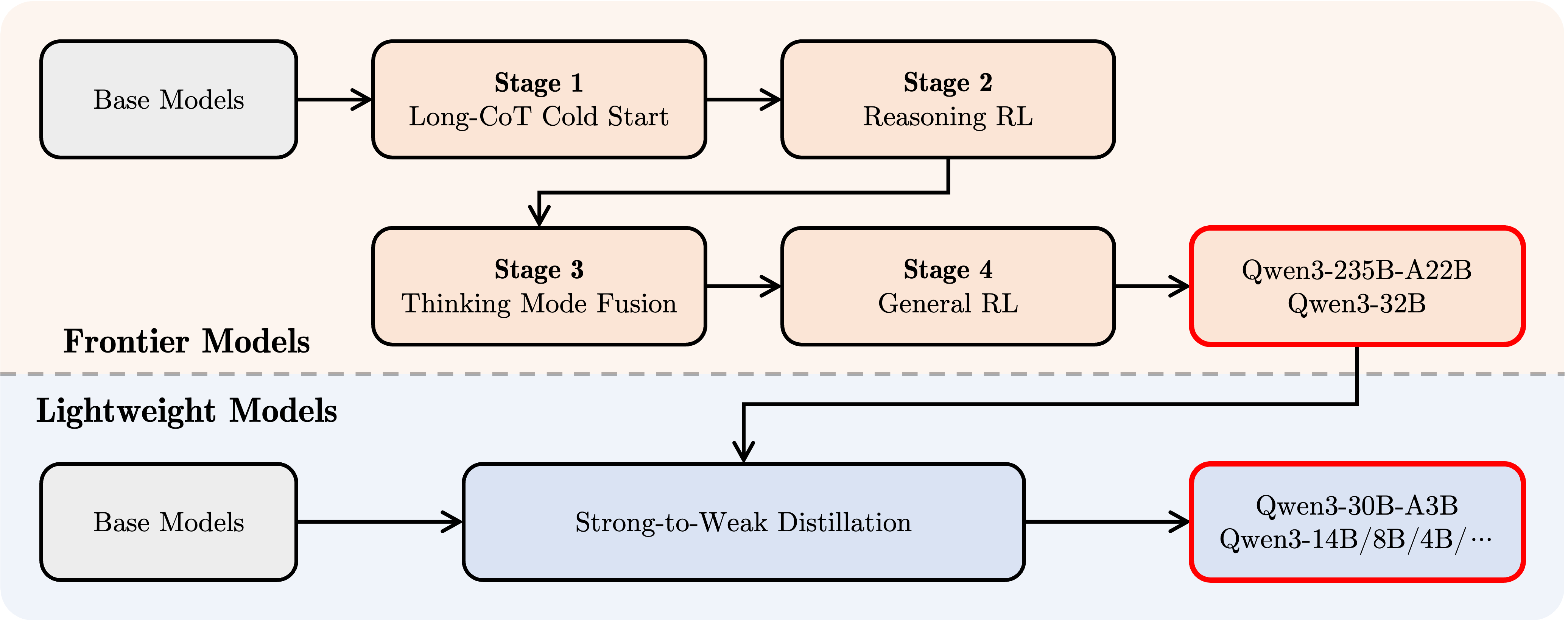
Long Chain-of-Thought (CoT) cold start: Fine-tuning with diverse long-step reasoning data from domains like math, coding, and logic to instill solid reasoning capabilities.
Reasoning-Based reinforcement learning (RL): Scaling RL with rule-based rewards to encourage better exploration and problem-solving.
Thinking mode fusion: Integrating non-thinking, fast-response skills by fine-tuning on a blend of reasoning data and typical instruction tasks, ensuring the model could switch between careful thought and quick answers.
General RL: Applying RL across 20+ general tasks to improve instruction following, formatting, and agent abilities while correcting undesirable behavior.
This comprehensive training approach equips Qwen3 to excel in both complex reasoning and real-time interactive scenarios.
Qwen3 Architecture
Qwen3’s architecture is a marriage of scale, efficiency, and flexibility, designed to maximize performance while managing computational cost.
Mixture-of-Experts (MoE) backbone: Instead of activating all parameters every time, Qwen3 uses MoE layers where only a small subset of experts fire per input, enabling massive parameter counts (like 235B in Qwen3-235B-A22B) while keeping actual computation per request much lower (22B active parameters). This sparsity is key to scaling without exploding costs.
Hybrid thinking modes: The architecture supports two modes “thinking” mode for in-depth multi-step reasoning that consumes more compute, and “non-thinking” mode for rapid, straightforward replies. This dynamic switching enables balancing speed and accuracy as needed.
Extended context windows: Qwen3 supports context lengths up to 32K tokens (and even higher in some variants), allowing it to maintain coherence over long conversations, documents, or codebases. This is made possible through optimizations in the transformer architecture and training on long-context data.
Multilingual and Multi-Modal support: Trained on 119 languages and various data formats, Qwen3 handles multiple languages fluently and is designed to integrate multi-modal inputs, like images, making it versatile across many application domains.
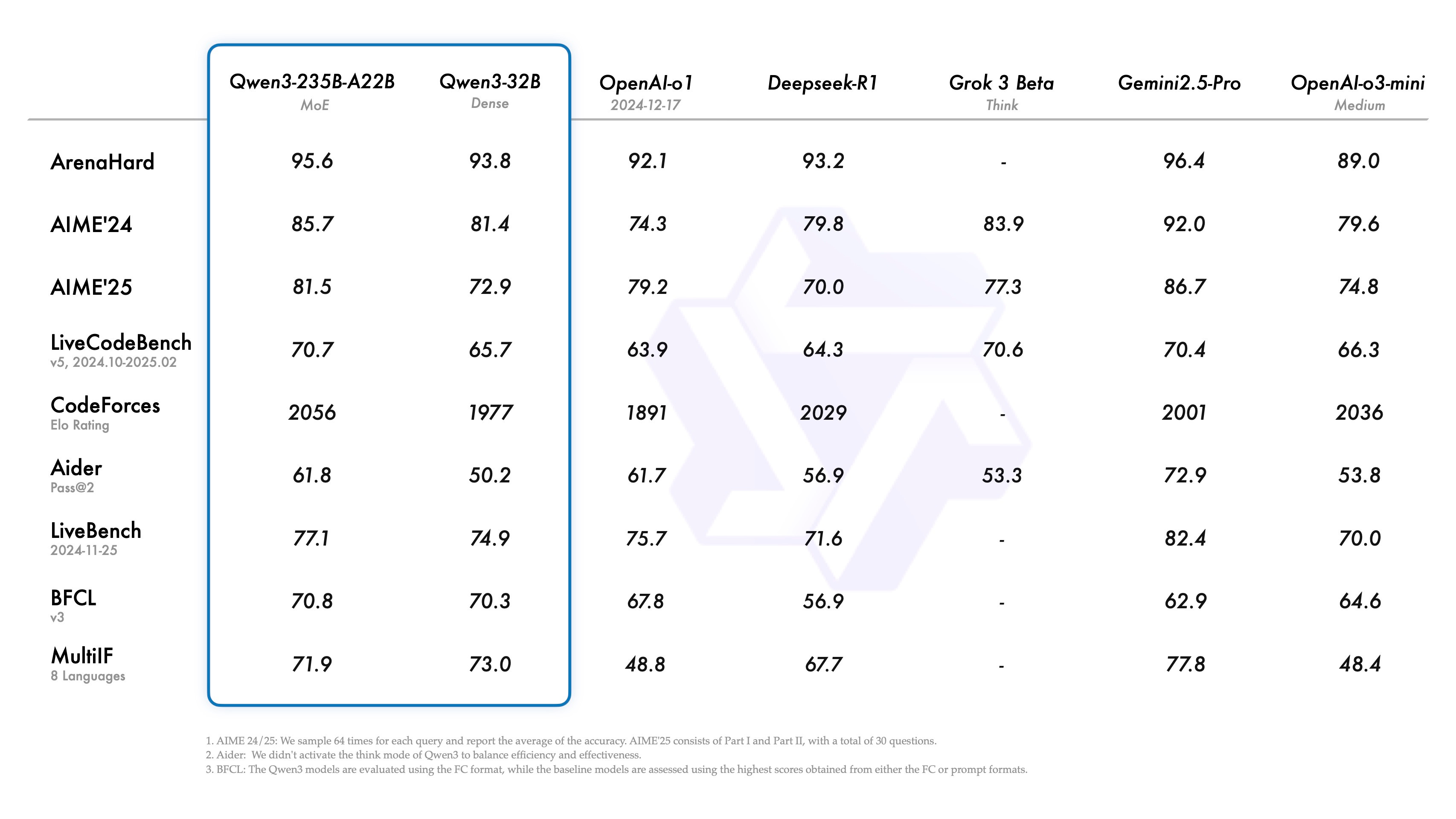
Qwen3 Benchmarks
When it comes to large language models, bragging rights come from benchmark scores but Qwen3 doesn’t just talk the talk; it walks the walk, often punching above its weight.
Conclusion
Qwen3 isn’t just another large language model trying to hog the spotlight it’s a carefully engineered family of AI tools designed to balance power, efficiency, and versatility. By leveraging Mixture-of-Experts architecture, supporting ultra-long contexts, and embracing multilingual capabilities, Alibaba has crafted something that scales smartly without sacrificing real-world usability.
Whether you’re a developer looking for an efficient 7B model for your chatbot, a startup needing robust 30B power with massive context windows, or an enterprise chasing cutting-edge AI with 235B parameters behind the scenes, Qwen3 has an option tailored to you.
Its benchmark performance proves it can hold its own and often excel against industry giants. Plus, Alibaba’s push for openness and cloud accessibility means this powerhouse won’t stay hidden behind closed doors for long.
In a world hungry for smarter, faster, and more adaptable AI, Qwen3 offers a refreshing new path forward. If you haven’t explored it yet, now’s the perfect time to dive in and see what this next-gen model family can unlock for your projects.

Until next time,
Stay curious, stay innovative and subscribe to us to get more such informative newsletters
Read more of WTF in Tech newsletter: