


10 GenAI/ML Questions to crack AI Interview in 2025 - Part 2
Guide to land the AI Engineer Job you always wanted!

Welcome back. In Part 1, we covered the kind of questions that already have hiring managers raising eyebrows and offers. But you're here for more. And rightly so.

In todays edition of Where’s The Future in Tech we’re cranking the realism up a notch. These questions are rooted in production-level firefighting, scaling decisions, hallucination wrangling, and retrieval rage. The kind of problems that happen not in notebooks, but in prod.
Ready? Let’s jump back into the interview arena.
1. How would you test the robustness of a multi-agent LLM system designed for collaborative task planning (e.g., autonomous research agents)?
What they're testing: Agent orchestration, robustness testing, prompt design under adversarial conditions.
Solution:
Testing multi-agent LLM systems is less like QA and more like managing an unpredictable cast in an improv play. The goal is to surface failure modes that emerge from coordination, not just from isolated behavior.
Start with role reversals: if Agent A is the planner and B is the executor, swap them mid-task and see how they react. Does B adapt or flounder? Introduce contradictions (e.g., one agent believes the task is done while another believes it’s pending) to check if agents can detect and resolve conflicts via dialogue.
Use adversarial prompts: plant misinformation, vague instructions, or conflicting goals. Does the system degrade gracefully? Or does it enter infinite loops or mutual blame spirals?
Use tools like conversation graphs to visualize agent exchanges. Loop detection can highlight coordination breakdowns. Also simulate real-world issues API timeouts, partial memory loss, or missing tools to test fallback planning.
Measure metrics like trajectory deviation (how far the final plan deviates from the original), task completion rate, and latency under perturbation.

2. You notice your LLM-powered coding assistant often autocompletes insecure code patterns. What’s your fix?
What they're testing: Security-aware LLM usage, fine-tuning strategies, prompt filtering.
Solution:
LLMs are trained on public code, and unfortunately, the internet is a treasure trove of insecure examples. To combat this, you need a multi-pronged defense.
Start at the prompt level: instead of asking for “code to connect to a database,” say “a secure way to connect to a database with prepared statements and error handling.” That guides the model toward safer defaults.
Then comes fine-tuning: curate a dataset with secure implementations (possibly annotated with CWE tags or vetted by linters like Bandit). A few hundred well-labeled examples can steer the model’s distribution significantly.
Finally, post-generation filters are critical. Use static analyzers like Semgrep or SonarQube to catch vulnerabilities before they're shown to the user. You could even incorporate a security classifier to block unsafe completions in real-time.
Set up a feedback loop: when developers flag unsafe suggestions, route them back into your fine-tuning set.
3. Your GenAI search assistant sometimes refuses to answer factual questions even when answers are in the indexed corpus. Why?
What they're testing: Generation behavior, confidence calibration, retrieval + prompting alignment.
Solution:
LLMs have a cautious side especially when you prompt them with “answer only if you’re 100% certain.” Sometimes, even when the right passage is retrieved, the model stays silent because it doesn’t recognize it as matching.
First, validate the retriever: is the answer actually being surfaced? If yes, inspect the generation prompt. Instead of rigid instructions, try:
“Based on the context, give your best guess even if it’s not explicitly stated.”
Next, analyze token attribution using tools like LLMTrace or AttentionViz. Sometimes, the model is retrieving the answer but paying attention to irrelevant tokens (like document headers or footnotes).
Also inspect decoding hyperparameters temperature too low, or penalties too high, can suppress valid completions. Consider generating multiple answers and reranking using entailment models or a confidence classifier.

4. Your LLM outputs are getting repetitive for creative writing tasks. How do you improve diversity without losing coherence?
What they're testing: Decoding strategies, creativity prompts, temperature tuning.
Solution:
If your LLM is sounding like a broken record, it’s probably stuck in a low-entropy groove. The fix starts with sampling tweaks: crank up temperature (0.9–1.2), reduce top-k, and use top-p sampling to let it explore more linguistic space.
Introduce diversity-promoting objectives: repetition penalty, distinct-n loss (which discourages repeating n-grams), or beam search with diversity augmentation.
On the prompting side, be specific: “Write a surreal short story with unexpected metaphors.” You can scaffold creativity by chaining prompts:
“Generate five weird but plausible plot ideas.”
“Pick one and write the opening paragraph.”
“Add a twist involving a dream sequence.”
Evaluate with distinct-2 or entropy per word, and sanity check coherence via rule-based validators or human-in-the-loop.
5. A production LLM API sometimes returns empty responses under high load. What’s happening?
What they're testing: Inference serving, system-level debugging, queue management.
Solution:
This smells like an infra issue likely a timeout or resource exhaustion. Under heavy traffic, your GPU memory might be full, or request queues might silently drop jobs if not configured with backpressure.
Inspect logs for signs of:
OOM errors
queue overflow
rate limits being triggered
token limit errors (long prompts silently failing)
Mitigations:
Add request-level tracing: timestamps for enqueue, dequeue, and decode.
Use vLLM or DeepSpeed-MII to shard requests and serve them efficiently.
If you're batching requests, ensure max token sizes are capped.
Consider implementing backoff and retry logic on the client side and serve partial responses when feasible.

6. How would you design a moderation layer to detect unsafe GenAI outputs across multiple languages?
What they're testing: Multilingual NLP safety, real-time moderation design, classifier integration.
Solution:
The challenge is both linguistic coverage and real-time throughput. Begin with language detection (e.g., FastText or LangDetect) to dynamically route the text through appropriate moderation channels.
Use XLM-RoBERTa or similar multilingual transformers fine-tuned for toxicity/offensiveness detection. Build a tiered system:
Fast path: Keyword regex + lexicon-based blocklist (fast but brittle).
Slow path: Transformer-based classifier that captures nuance, sarcasm, coded language.
For higher adaptability, store flagged generations and let human reviewers annotate them. Use this growing dataset to continually fine-tune your classifiers.
You’ll also want real-time performance, so deploy the moderation model using ONNX or TensorRT for low-latency inference.

7. Explain how you would design a GenAI-powered tutor that adapts to a student's learning style over time.
What they're testing: Personalization in LLMs, curriculum learning, user embedding strategies.
Solution:
Every student has a unique cognitive fingerprint. You need to build a dynamic learner profile an embedding updated with each interaction based on quiz performance, confusion points, and engagement metrics.
Use this profile to condition prompts:
“The student struggles with visual reasoning. Use analogies and diagrams where possible.”
Adopt curriculum learning: start with basic concepts and increase complexity as mastery improves. Train a difficulty classifier to rate questions and route students accordingly.
Detect learning styles using question-answering logs: e.g., does the student prefer examples first, or definitions? Adjust content accordingly (e.g., analogy-heavy for abstract learners).
Use vector databases like Weaviate or Pinecone to store interaction history and retrieve personalized context.

8. A GenAI image captioning model tends to miss important visual details. How would you improve it?
What they're testing: Multimodal fusion, visual grounding, attention mechanisms.
Solution:
This usually points to weak grounding between the vision encoder and text decoder. One fix: fine-tune on datasets where each caption is tightly aligned with detected regions (e.g., MS-COCO with bounding boxes).
You can enhance visual grounding by fusing outputs from object detectors (like DETR or YOLOv8) and feeding entity tags into the captioning prompt.
Use contrastive learning during fine-tuning (e.g., CLIP-style loss) to make sure the text representation moves closer to the correct image embedding than to others.
Visualize attention heatmaps to confirm what parts of the image the model is focusing on. If it’s stuck on sky/background, retrain with region-level supervision.

9. Your RAG system is great at answering FAQs, but fails on long-tail, rare queries. How do you improve this?
What they're testing: Retrieval optimization, tail coverage strategies, hybrid approaches.
Solution:
Long-tail failure is often due to dense retrievers underfitting rare terms. First, make your retrieval stack hybrid: fuse BM25 (sparse) with dense embeddings (e.g., from BGE). Use reciprocal rank fusion (RRF) or cross-encoders to rerank the top results.
Next, perform query expansion using an LLM: for each rare query, generate paraphrases that better match corpus phrasing. You can even use a query rewriter agent in your pipeline.
Train the retriever on hard negatives (documents that are close but irrelevant), so it learns subtle differences.
Use Recall@k for tail queries as your target metric. To generate such tail queries, scrape support logs or forum data.
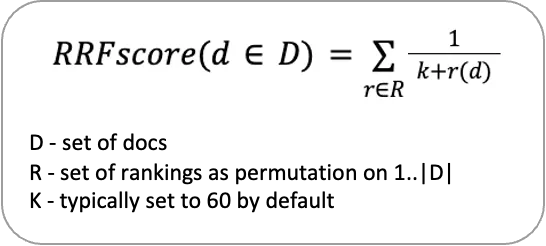
10. A product team wants to use a vision-language model to create Instagram captions from photos. How do you ensure the captions match the brand’s personality?
What they're testing: Multimodal prompt conditioning, brand tone alignment.
Solution:
Brand tone is everything. Capture it by building a tone profile prompt a few-shot setup with past successful captions. For example:
“Input: photo of a dog on a beach
Output: ‘CEO of chilling hard today.’”
Use this profile during inference. For better results, fine-tune the language head on brand-specific datasets, keeping the vision encoder (e.g., from BLIP-2 or Flamingo) frozen or LoRA-tuned.
Integrate a semantic grounding module: extract scene entities (e.g., ‘sunset’, ‘surfboard’) and push those tokens into the decoder’s attention.
Evaluate captions with CLIPScore for relevance and use a brand tone classifier (trained on positive/negative feedback) for style consistency.
Wrapping Up
These questions go way beyond textbook theory they're the kinds of curveballs that show up when you're building GenAI systems in the wild. They test how you handle ambiguity, failure, alignment, and scale exactly what top AI roles in 2025 demand.
If you can walk through these problems confidently, you're not just interview-ready you’re battle-tested for real-world AI work.
So study them, talk through them, even prototype a few. The GenAI world is evolving fast, and the best way to stand out is to show you can think like a builder not just a learner. Keep exploring. Keep iterating. The future’s being built token by token.

Until next time,
Stay curious, stay innovative and subscribe to us to get more such informative newsletters
Read more of WTF in Tech newsletter: