


Reward Models in LLMs
How AI Learns What Humans Want..

LLMs are great at generating text but how do we teach them what’s “good”? Not in the grammatical sense, but in the human one: helpful, harmless, honest. That’s where Reward Models (RMs) come in. They’re the evaluation engines behind alignment, shaping how language models evolve from token predictors to socially competent assistants.

In this edition of Where’s The Future In Tech, we’ll break down what reward models really are, how they work, the math behind them, their architecture variants, their strategic importance in RLHF, and what’s next for this vital alignment component.
What is a Reward Model?
At its core, a Reward Model is a neural network that assigns a score to an LLM’s output, reflecting how well it aligns with human preferences. This score acts like a stand-in for human judgment informing learning without needing humans in the loop for every decision.
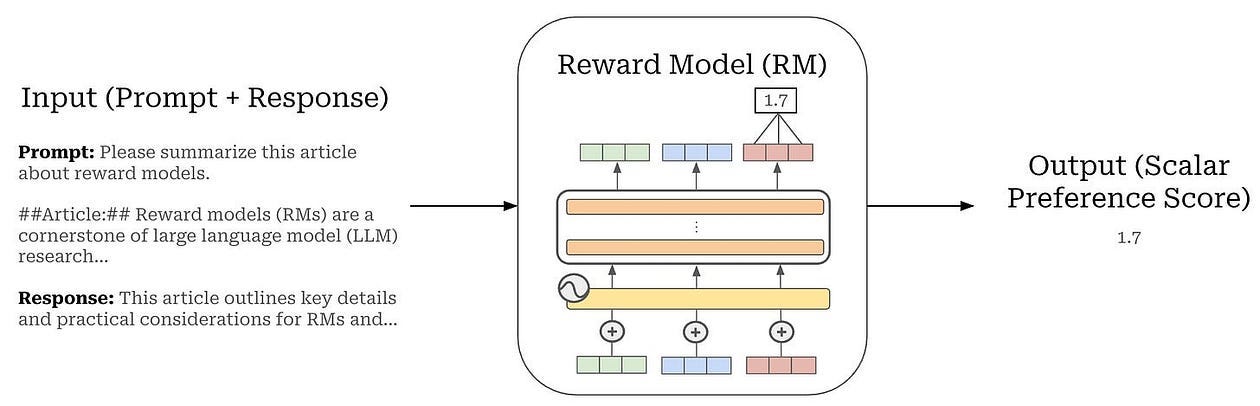
Think of a reward model as a learned preference function. Where a language model tries to predict words, a reward model tries to predict human approval.
It takes two inputs:
A prompt (the user’s question or instruction)
A candidate response (something the LLM has generated)
And produces one output:
A score, usually a single real number. The higher the score, the more a human would prefer that response.
But how does it know what humans prefer?
Through pairwise comparison data: humans are shown multiple outputs and asked, “Which one is better?” The RM learns from thousands (or millions) of these comparisons until it can approximate human judgments on unseen prompts. This means the RM becomes a proxy for human feedback letting us train the big language model with reinforcement learning without needing constant human labels.
Why Reward Models are useful
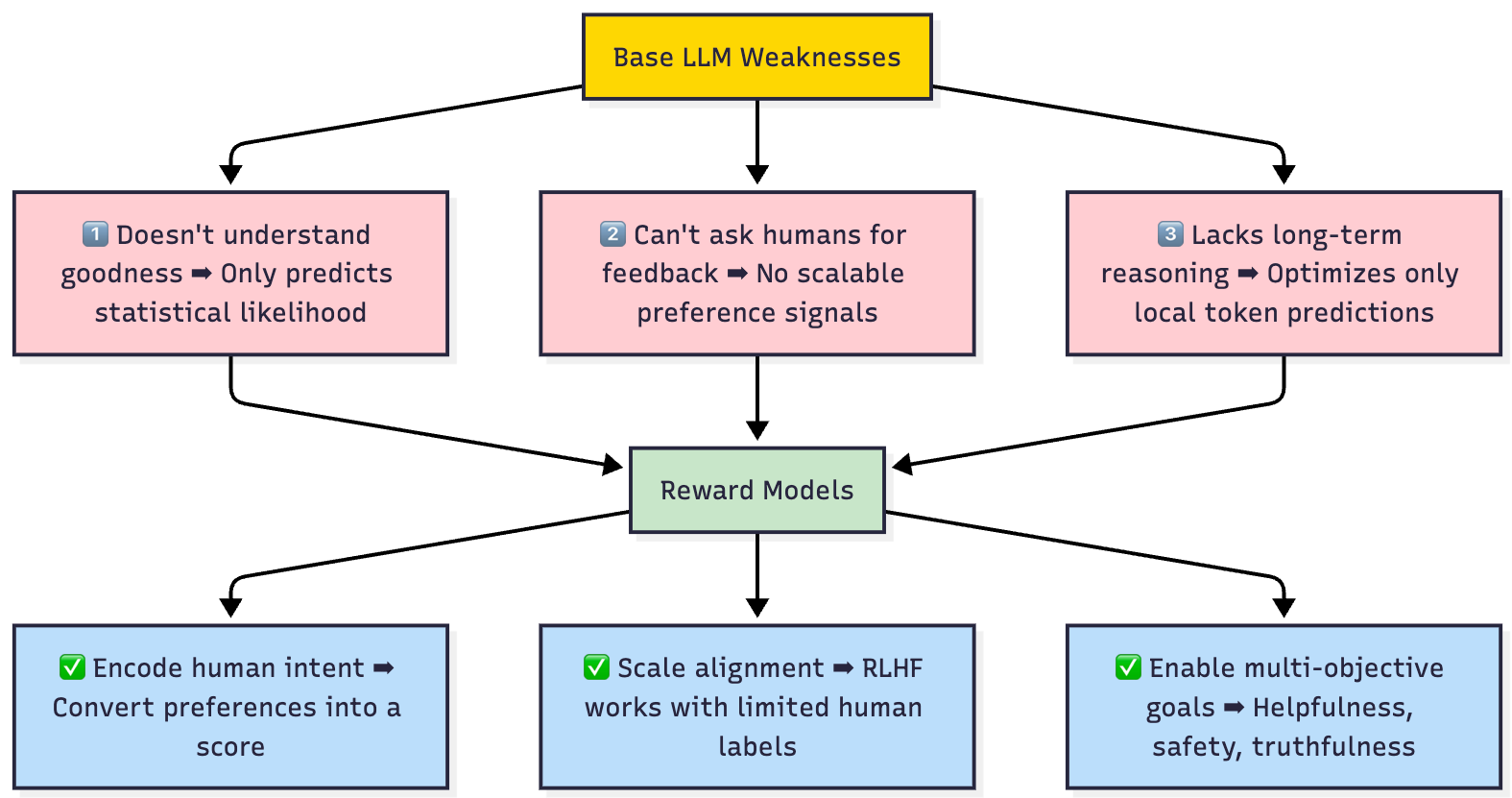
Base LLMs have three big weaknesses:
They don’t understand “goodness”, only statistical likelihood.
They can’t ask humans for feedback at scale during training.
They don’t reason about long-term preferences, just local token predictions.
Reward Models solve all three:
They encode human intent into a machine-readable score.
They scale alignment, so reinforcement learning can work with limited human data.
They enable multi-objective goals (helpfulness, safety, truthfulness) instead of just raw fluency.
Without RMs, InstructGPT wouldn’t exist, ChatGPT wouldn’t know what “helpful” means, and safe AI assistants would be nearly impossible to build.
The architecture of a Reward Model
A Reward Model is not a new kind of neural network; it’s a repurposed LLM turned into a scoring function. Here’s how it works internally:

1 Transformer backbone
Shared DNA with the base model:
Most RMs start from the same architecture and weights as the LLM policy model (e.g., GPT, LLaMA). This ensures the RM understands language context just as well as the model it evaluates.Input format:
The prompt and candidate response are concatenated into a single sequence:[Prompt] + [Response]This lets the transformer process both parts in context.
Attention layers:
Each transformer block computes contextual embeddings for every token. By the final layer, each token has a high-dimensional vector summarizing its meaning, its relation to the prompt, and the rest of the response.
2 Reward head
After the transformer produces embeddings, a regression head is added.
This is usually a simple linear layer:
\(s = Wh_{final} + b\)where
\(h_{final}\)is the final hidden state of the last token or a special classification token.
The output scalar sss is the predicted reward for this prompt-response pair.
3 Score normalization
For a given prompt, multiple candidate responses are scored.
Scores are often normalized to zero mean and unit variance to make pairwise comparisons stable.
This ensures the RM focuses on relative quality, not absolute magnitude.
4 Training objective (Pairwise Loss)
Given a human preference pair
\((y_w,y_l)\)the model should score the “winner” higher than the “loser”.
Using the Bradley-Terry model, the loss is:
\(L = -log σ(r(x,y_w) - r(x,y_l))\)This pushes the difference in scores upward whenever humans pick yw.
Over time, the RM learns a latent preference function that generalizes beyond seen examples.
5 Intuition
The RM doesn’t generate text it judges it.
It’s like a movie critic who’s watched thousands of films. The critic doesn’t direct new movies but knows what makes a good one.
This separation of generator and evaluator is what makes RLHF possible.
The Bradley-Terry Model of Preference
The BT model is the mathematical backbone of RMs. It assumes every item (response) has a latent quality score. The probability one item wins is proportional to its score relative to the competitor.
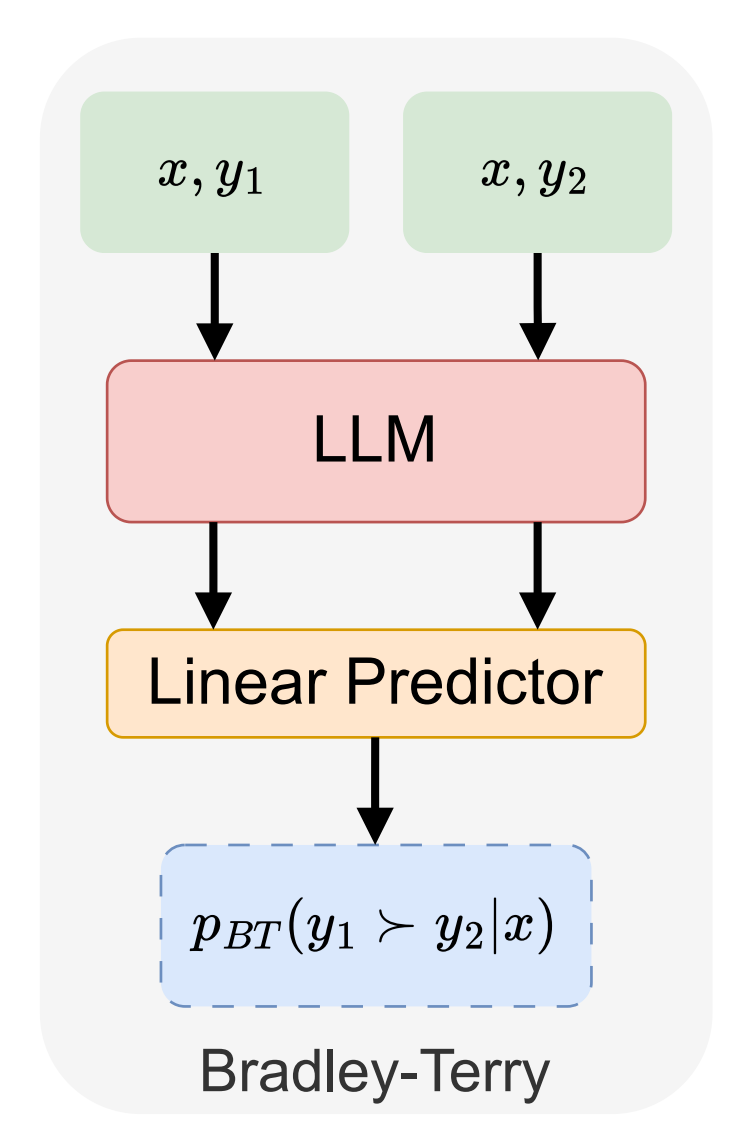
Why it works well for RMs:
Captures relative preference, not absolute ratings.
Works even when annotators disagree on numeric scores.
Produces smooth gradients for optimization.
Alternative approaches:
Plackett-Luce model (for >2 options)
Margin ranking loss
But BT remains the default due to simplicity and empirical success in InstructGPT and successors.
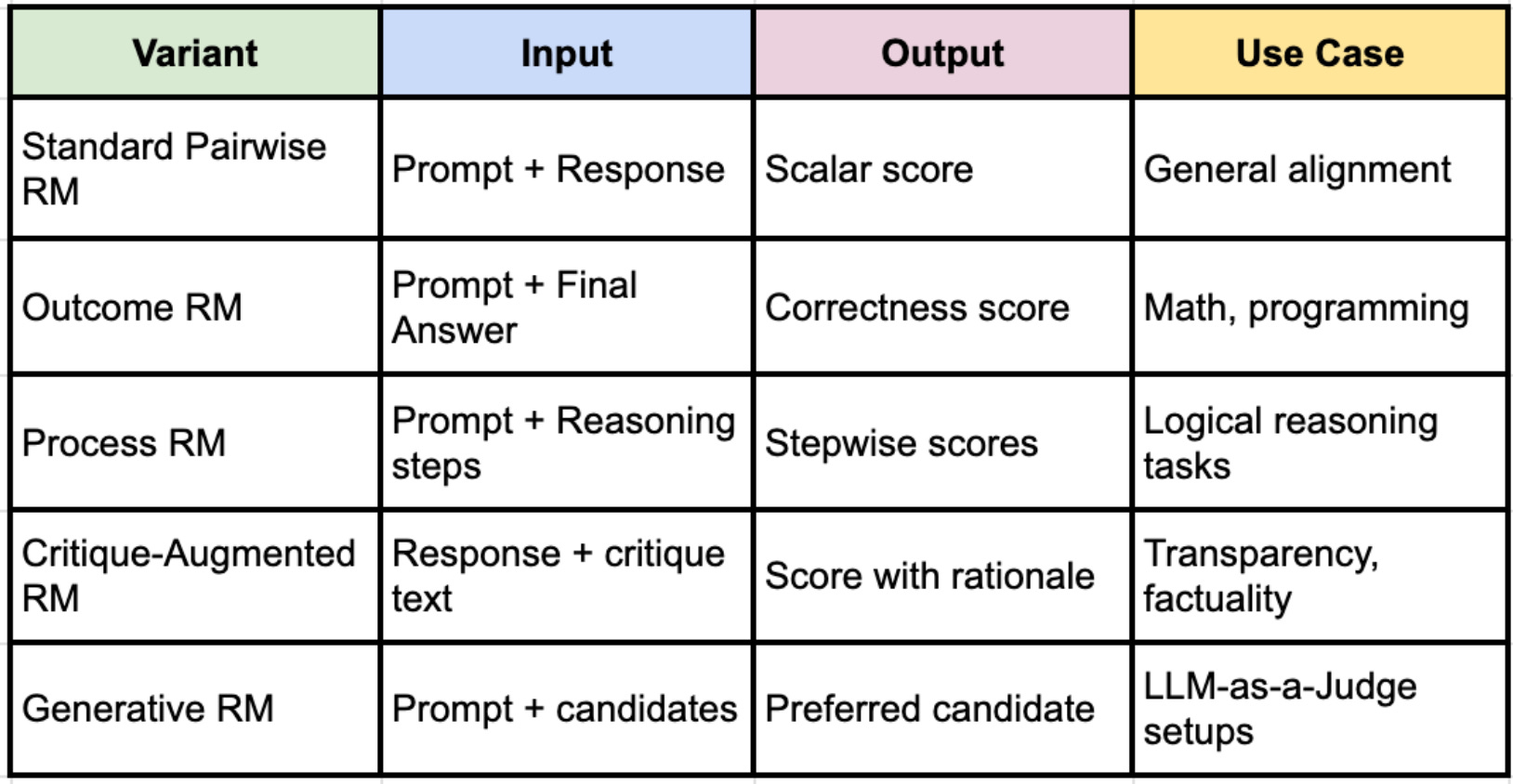
Architectural Variants
Not all RMs are built equal. Depending on the task, different architectures emerge:
1. Outcome Reward Models (ORM)
Judge only the final answer.
Used in math/code tasks where correctness is the only metric.
Cheaper to train but blind to flawed reasoning paths.
2. Process Reward Models (PRM)
Score intermediate reasoning steps, e.g., chain-of-thought outputs.
Helps models learn better reasoning strategies, not just final answers.
Vital for models trained to "think step-by-step."
3. Critique-Augmented Models
Add a “critique” phase where the RM (or an auxiliary model) generates an explanation of why an answer is good/bad before scoring it.
Makes the scoring more interpretable and less arbitrary.
Example: RM-R1 improves factuality by explicitly reasoning about truthfulness.
4. Generative Reward Models
Instead of outputting a scalar, the model produces a verdict (“Response A is better than Response B”) or a reasoning chain.
Used in LLM-as-a-Judge frameworks.
5. Multi-Objective and Ensemble RMs
Multiple reward heads: helpfulness, safety, harmlessness.
Weighted or dynamically combined.
Helps avoid the trade-off where a single scalar optimizes only one goal.
Types of Reward Models
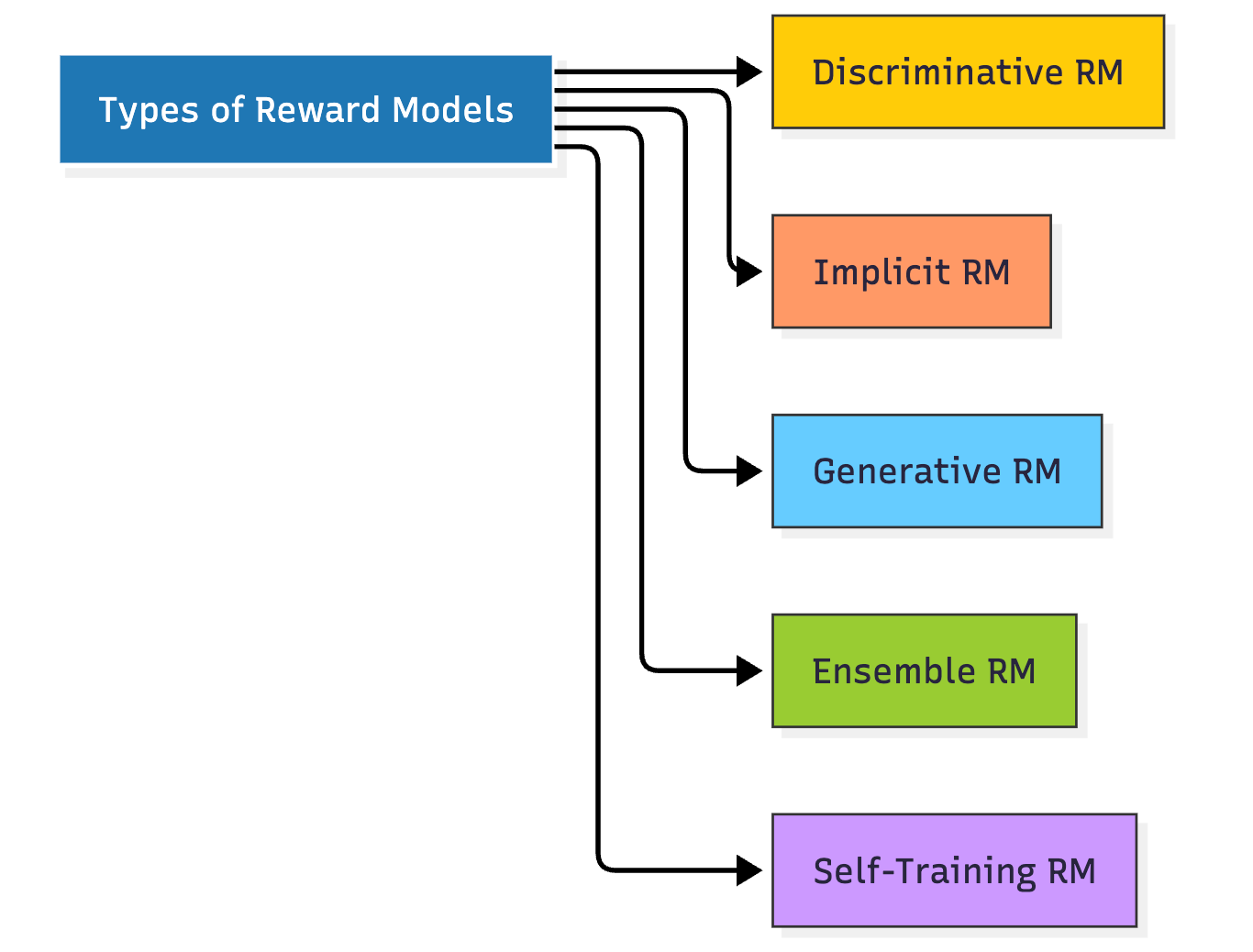
Based on training and deployment:
Discriminative RM: Standard scalar scoring models (most common).
Implicit RM: Preferences are baked directly into the policy via methods like Direct Preference Optimization (no separate RM needed).
Generative RM: LLM judge generates rankings/explanations.
Ensemble RM: Multiple RMs reduce bias and reward hacking.
Self-Training RM: Uses synthetic comparisons when human data is limited.
How Reward Models Fit Into the RLHF Pipeline
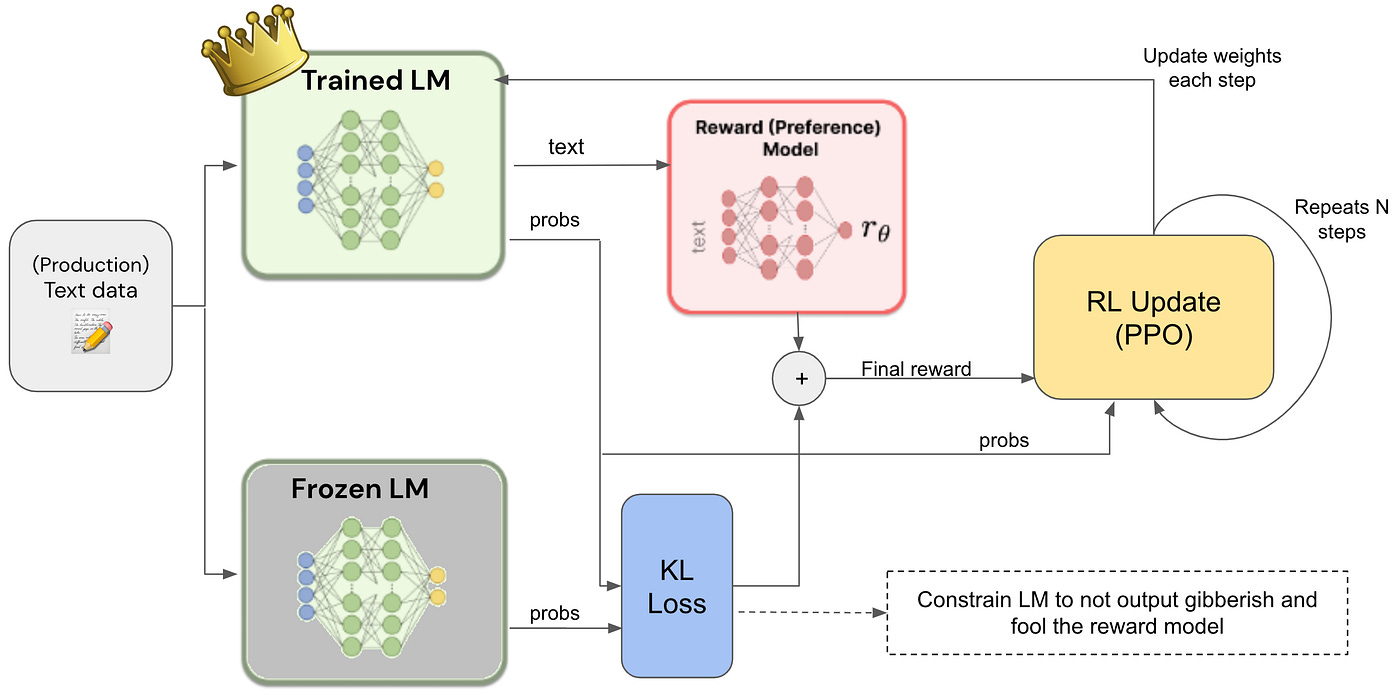
The RLHF pipeline integrates RMs to align LLMs:
Supervised Fine-Tuning (SFT)
Base model is trained on curated prompt-response pairs.Data Collection
Humans compare multiple responses for a prompt.Train Reward Model
Use BT loss to make the RM reflect human preferences.Reinforcement Learning (PPO)
The RM acts as the reward function. The policy model updates its parameters to maximize expected reward while staying close to the base model (via KL penalty).Evaluation and Iteration
Continuous feedback loops to refine RM and policy.
Without RMs, this loop would collapse we couldn’t scale human feedback effectively.
Challenges and Strategic Enhancements
Reward Hacking: Models learn to exploit RM quirks instead of improving quality.
Bias & Subjectivity: Different annotators = inconsistent preferences.
Sparse Data: Limited human labels make RMs brittle.
Distribution Shift: RMs fail on unseen domains.
Solutions:
Ensembles for stability.
Synthetic feedback (LLMs critiquing themselves).
Uncertainty-aware RMs (predicting confidence).
Iterative refinement with online feedback loops.
RM Architecture at a glance
Final thoughts
Reward Models are the invisible glue between raw prediction power and human-aligned behavior. They transform probability machines into assistants that understand quality, not just likelihood. Future RMs will likely:
Be process-aware by default, scoring reasoning chains dynamically.
Use self-training to scale beyond human annotation bottlenecks.
Evolve into interactive judges, guiding generation step-by-step instead of just scoring after the fact.
In other words, RMs are more than just scoring functions they’re becoming the conscience of AI systems, deciding not what AI can say, but what it should say.
Until next time,
Stay curious, stay innovative and subscribe to us to get more such informative newsletters.