
Reinforcement Learning for LLMs - Part 1
Teaching LLMs to behave, deep dive into reinforcement learning for large models

As AI continues to make strides, language models have become more capable, powerful, and intelligent. But there's one major challenge we all face: how do we ensure these models behave in a way that aligns with human values? After all, we're not just teaching them language, we're teaching them to think, communicate, and make decisions that are in harmony with the real world. Enter Reinforcement Learning (RL) for LLMs an incredibly important tool to fine-tune LLMs so they don’t just spit out text, but do so in an ethical, helpful, and safe manner.

In todays edition of Where’s The Future in Tech, I’m diving deep into the architecture and flow of reinforcement learning for LLMs and breaking down the four-step process that helps align these powerful models with human preferences.
Understanding the Need for Alignment in LLMs
Think that you've trained a language model to generate answers. It can answer questions, create content, and even hold conversations. But here’s the problem: the model doesn’t have a built-in understanding of what is good or bad behavior it’s just mimicking patterns. What if it generates offensive or harmful content? Or gives you irrelevant information? That’s where alignment comes into play.
Alignment refers to training the model to ensure that its outputs are useful, ethical, and safe for human users. While we want our LLMs to be powerful, we also want them to reflect human ethics and values, which is no small task. This is where Reinforcement Learning comes in, ensuring that LLMs not only generate language but do so in a way that aligns with what we want.
The Issue with Pre-trained Models
While pre-trained models provide a strong starting point, they lack the moral compass we need. Here’s why:

Bias and Toxicity: Pre-trained models are trained on massive datasets scraped from the web. These datasets are far from perfect they contain biases, stereotypes, and even offensive content. Without any corrective measures, the model might unknowingly reproduce this content.
Moral and Ethical blind spots: Even though pre-trained models can generate text that sounds fluent and natural, they don’t have an understanding of ethical boundaries. They can offer technically accurate answers but fail to navigate sensitive issues in a socially acceptable way.
Lack of human alignment: Pre-trained models might output facts that are true in a statistical sense, but they don’t align with the nuances and preferences of human users. The language might be correct but not always appropriate or contextually sensitive.
Thus, pre-trained models alone can’t be trusted for real-world applications. That’s where RLHF steps in, guiding them toward human-aligned behavior.
What is Reinforcement Learning (RL)?
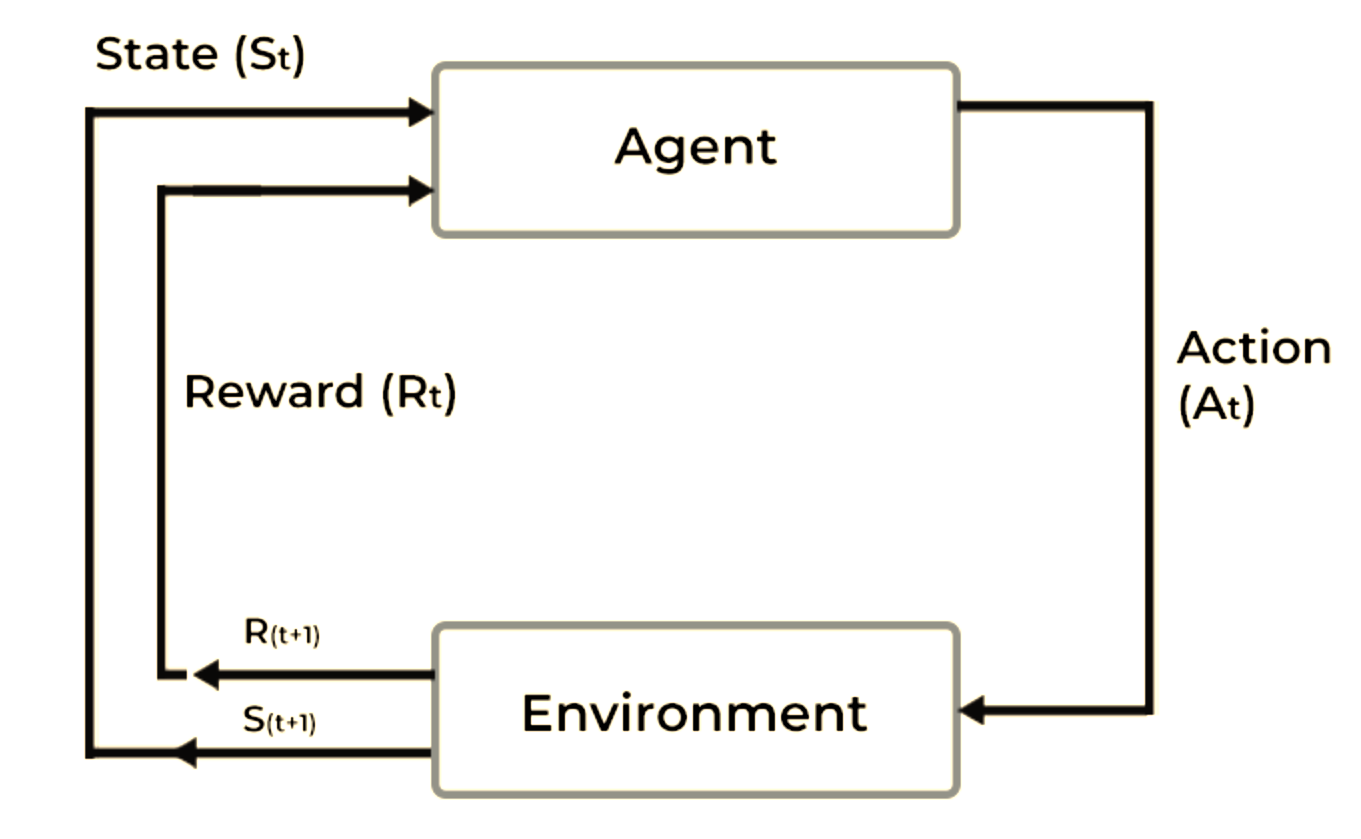
At its heart, Reinforcement Learning (RL) is a type of machine learning where an agent learns to make decisions by interacting with an environment.
Think of it like training a dog:
You give it a treat when it sits on command (reward ✅)
You ignore or correct it when it jumps on guests (punishment or lack of reward ❌)
Over time, the dog learns which behaviors are good and which are bad because it’s trying to maximize its rewards.

Now, replace the dog with a machine (like a robot or an AI model), and you have the basic idea of reinforcement learning.
The cycle looks like this:
The agent observes the environment.
It takes an action.
It receives a reward (good or bad) based on that action.
It updates its strategy (policy) to improve future decisions.
Repeat thousands, millions, or even billions of times.
The Architecture Behind Reinforcement Learning for LLMs
Before we get into the four-step process, let’s take a look at the architecture that makes reinforcement learning for LLMs possible. This process involves several components that work together like gears in a machine, each one contributing to the overall alignment of the model.
Here’s a breakdown of the key components:
Base model: This is the initial, pre-trained version of the language model. It understands language but lacks human alignment.
Supervised fine-tuned model: Built from the base model and trained on a curated dataset of human-labeled examples, this model begins to learn what “good” looks like in terms of responses.
Reward model: The reward model learns from human feedback, evaluating the responses generated by the model and providing scalar feedback based on how well it aligns with human expectations.
Policy model: This is the final version of the model. After training with reinforcement learning, it uses feedback from the reward model to generate responses that align with human preferences.
Each of these steps is integral to creating a model that is capable of generating helpful and ethical responses. But the magic happens in how they work together.
The Four-Step Process to Align LLMs
To take the model from raw language generation to aligned, helpful behavior, there’s a four-step process that begins with training the model and ends with a fine-tuned, policy-driven system. Let’s go step by step and dive deeper into each phase.
Step 1: Pre-training the Base Model
Before you can align a model with human values, you need to give it a solid foundation. This is done in the pre-training phase, where the model learns the basics of language.
What happens in Pre-training?
The model is exposed to vast amounts of text data think books, websites, and articles. Its primary task is next-word prediction, meaning it learns to guess what word comes next in a sentence based on the context. By doing this, the model gains a deep understanding of language structure, grammar, and even some facts about the world.
Outcome of Pre-training:
At this stage, the model is capable of generating human-like text, but it’s neutral. It knows how to form sentences, but it has no understanding of right or wrong responses. It can generate accurate but also potentially biased or inappropriate outputs.
Pre-training is essential as it gives the model the language ability necessary to generate coherent, contextually accurate responses.
Step 2: Supervised Fine-Tuning (SFT)
Now that the base model knows how to generate text, we need to start shaping its behavior. That’s where supervised fine-tuning comes in.
What is Supervised Fine-Tuning?
The model is retrained using a more curated dataset that’s specifically designed to teach the model what good behavior looks like. Human annotators provide examples of ideal responses, such as helpful answers, polite conversation, and factually correct information.
Outcome of Supervised Fine-Tuning:
The model starts learning what makes a response appropriate for specific contexts. For example, if you ask about the weather, the model learns to answer politely and correctly. This step helps improve the model’s ethics and usefulness. However, it’s still relatively static. While it’s better at generating human-aligned content, it isn’t learning from ongoing feedback yet.

Supervised fine-tuning is the first real step toward aligning the model’s behavior with human values, but it’s not the end of the road.
Step 3: Reward Model and Human Feedback
Here’s where things get interesting. In this step, we introduce the Reward Model, which begins incorporating feedback from humans to evaluate and improve the model’s responses.
What is the Reward Model?
The reward model is a clone of the base model but trained to predict a scalar value that represents how well a given response aligns with human values. Humans compare different responses generated by the model and rank them based on factors like politeness, helpfulness, correctness, and safety.
Outcome of the Reward Model:
The model now has a mechanism to judge its responses. Based on these rankings, it learns to self-assess whether its output is acceptable or needs improvement. The reward model's feedback helps the model understand how to improve itself in real-world applications, pushing it closer to human-like ethical reasoning.
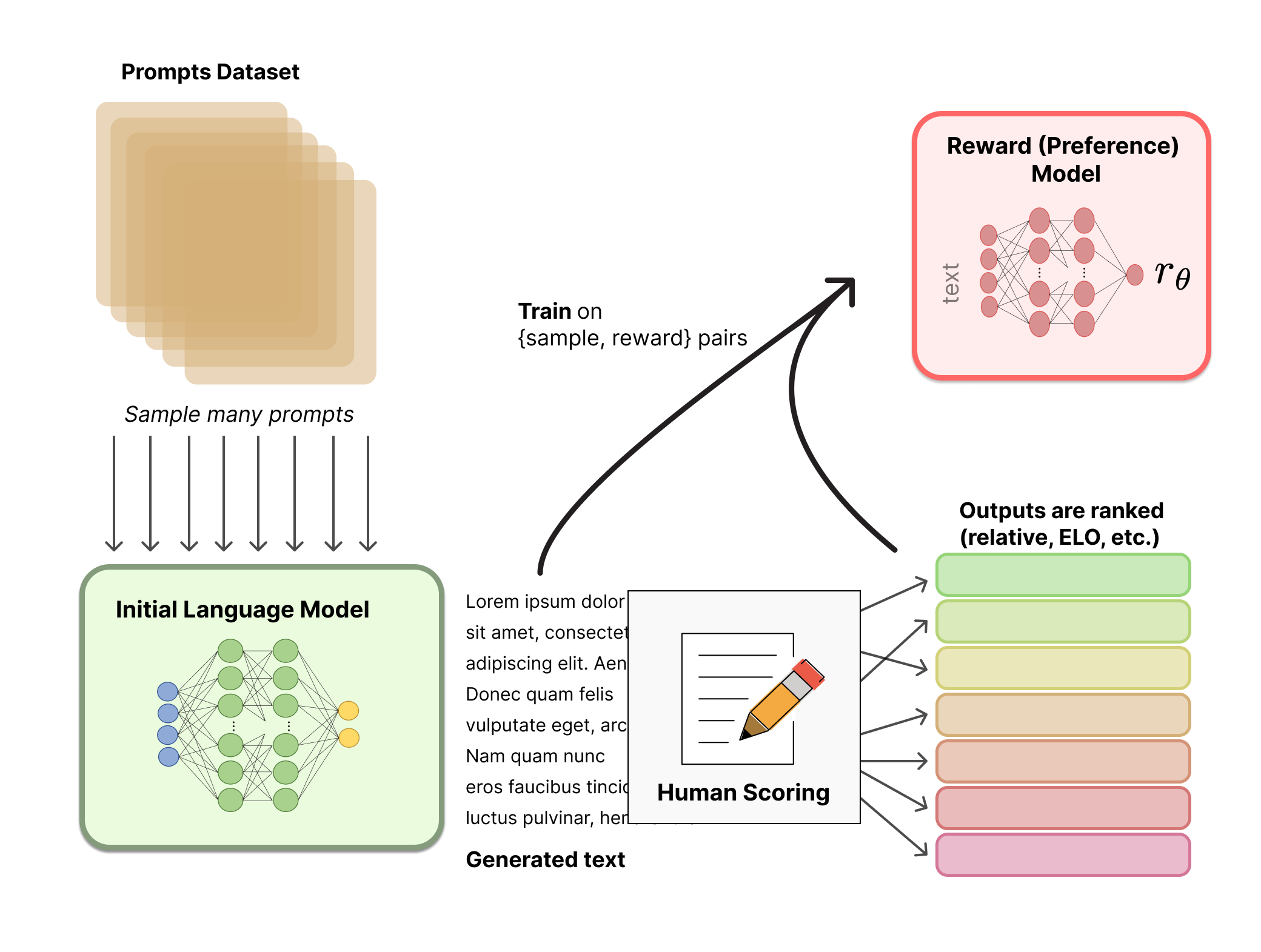
This step is crucial because it adds a layer of evaluation that helps the model understand what humans actually prefer.
Step 4: Reinforcement Learning with PPO
At this stage, the model has learned some basics from humans, but we need to refine it even further. This is where Reinforcement Learning (RL) kicks in, specifically through the use of Proximal Policy Optimization (PPO).
What is PPO?
PPO is an RL algorithm that helps the model improve through feedback from the reward model. It adjusts the model’s responses based on how well it scores in previous iterations. The model generates responses to various prompts, receives feedback from the reward model, and then updates itself to maximize these feedback scores.
Outcome of PPO:
The model continuously refines its responses to better align with human preferences. Over time, it gets better at generating text that is polite, helpful, and factually accurate without any direct human intervention.

The PPO process ensures that the model is constantly evolving and becoming more aligned with human values, adjusting based on real-time feedback.
Continuous Learning and Alignment
The four steps we’ve discussed Pre-training, Supervised Fine-Tuning, Reward Model, and Reinforcement Learning with PPO are part of a continuous learning cycle. After the model is deployed, it keeps learning from new data and feedback, further refining its ability to produce ethical and useful content.
This cycle is what allows LLMs to become more than just static systems. They can adapt to new situations, improve over time, and become more aligned with the needs and values of human users.
The Strengths of RLHF
The introduction of reinforcement learning into the training pipeline brings several distinct advantages:
Real-Time adaptation: RLHF allows models to continuously adapt and improve based on real-world feedback. Unlike traditional training, where updates are done in batches, RLHF enables the model to learn from its mistakes and refine its behavior in real time.
Personalization: By using human feedback, the model can be tuned for specific domains or tasks. For example, the model could be trained to behave differently in customer service compared to medical advice, ensuring that it is more contextually aware.
Ethical alignment: RLHF allows for a more human-centric approach to training. By integrating human preferences into the model’s learning process, the model’s behavior can be aligned with ethical standards and social norms. This helps eliminate biases and inappropriate content generation.
Continual improvement: Since the reward model constantly evaluates the model's output and provides feedback, the LLM can evolve over time to handle more complex scenarios and stay in line with evolving human expectations.
Challenges and Alternatives
While RLHF is a powerful tool, it’s not without its challenges. Some of the most notable hurdles include:
Scalability: Collecting enough human feedback can be resource-intensive. Human evaluators are needed to rank outputs, and this can quickly become expensive and time-consuming.
Data quality: The feedback we provide to the model must be high quality. If human evaluators are inconsistent or if the feedback is unclear, the model’s training could suffer. Ensuring that feedback is accurate and well-calibrated is a challenge in itself.
Ambiguity in preferences: Humans don’t always agree on what’s “best.” A model may face conflicting feedback what one human thinks is a great response, another might find offensive or biased. Handling these subjective differences can be tricky.
Alternatives:
Unsupervised reinforcement learning: Instead of relying on human feedback, models can be trained using unsupervised methods, where they optimize for specific goals without direct human evaluation. However, this approach can lead to the model drifting away from human alignment if not properly regulated.
Imitation learning: Another alternative is imitation learning, where the model tries to mimic human behavior based on a dataset of expert actions. This can be useful, but it doesn't allow the model to continuously improve or adapt as easily as RLHF.
Inverse reinforcement learning: This technique involves learning from the actions of humans rather than explicit feedback. While powerful, it can be computationally expensive and difficult to scale.

Why This Matters Today
As AI continues to play a larger role in our daily lives, ensuring that models are aligned with human values is becoming increasingly critical. Here’s why RLHF is particularly important now:
Wider AI deployment: LLMs are being integrated into more applications healthcare, education, law, and entertainment, just to name a few. With this comes the responsibility of ensuring that these models act ethically and don’t cause harm.
Human-Machine collaboration: As AI systems take on more tasks, they’ll need to work alongside humans in a collaborative manner. Models need to be trained not just to understand language but also to understand human intentions, feelings, and preferences.
Accountability and transparency: As these models begin to make decisions with real-world implications, it’s important that we can trace back how and why a model made a particular decision. RLHF provides a pathway for making these systems more accountable and transparent.
Conclusion
Reinforcement Learning for LLMs isn't just about making models more intelligent. It’s about making them more ethical, useful, and safe. By combining pretraining, fine-tuning, reward models, and reinforcement learning, we create models that don’t just generate text they generate text that makes sense in a human context.
With this approach, we ensure that LLMs behave the way we want them to. They’re not just producing text that’s statistically likely, they’re producing text that’s aligned with our values. This ongoing process of learning, adapting, and improving is what will shape the future of ethical AI systems.
I hope this guide gives you a solid understanding of how reinforcement learning aligns large language models and why it’s such an important part of the development process. In the next part we’ll cover various types of RL algorithms in detail.

Until next time, stay curious and keep learning!
You compare it to a dog; I compare it to a child. I enjoyed reading your article. It’s very easy to follow for the non-technical readers. I you have the time, I would welcome your thoughts on the following: https://dal1m.substack.com/p/my-ongoing-turing-test-part-i-the