
Object Detection with Large Vision Language Models (LVLMs)
Object detection, now smarter with LVLMs


Think of asking AI to "find the red apple" in an image and watching it detect the object with pixel-level precision without needing predefined labels.
Welcome to this edition of Where’s The Future In Tech newsletter, where we delve into the transformative world of object detection powered by Large Vision-Language Models (LVLMs).
Curious how it works? Let’s break it down!

What We’ll Cover
In this edition, you’ll learn:
How LVLMs interpret natural language prompts for object detection.
The hybrid approach of LVLMs + traditional computer vision.
How LVLMs achieve precise object localization.
Key trade-offs between LVLMs and conventional object detection.
Real-world applications across industries.
Conventional Object Detection: The Old Way

Custom Object Detection with YOLO V5
Before LVLMs, object detection was a tedious, time-consuming process. If you wanted to train a model to recognize objects, you had to label thousands, sometimes millions of images manually. It was a slow grind. Training these models took weeks, and even after all that effort, they could only recognise what they were explicitly trained on. If a new category came up, you had to go back to square one, retrain the model, and hope it generalises well enough.
Let’s take a look at how things used to be:
Tedious data annotation: Every object in an image had to be labeled by hand. Imagine manually drawing boxes around thousands of cars, apples, or coffee mugs it was as exhausting as it sounds.
Weeks of training: Once labeled, models like YOLO, Faster R-CNN, and SSD had to be trained on high-performance GPUs for long periods.
Limited generalization: If a model wasn’t trained to recognize a new object (say, an unusual species of bird), it simply wouldn’t detect it.
Rigid pipelines: Adding new categories meant going back and retraining, making the whole process inefficient and frustrating.
LVLMs are here to change all that. They don’t just detect objects they understand them in context. Let’s see how they work.

What Are LVLMs?
Large Vision-Language Models (LVLMs) are a new class of AI systems that can process both visual and textual information simultaneously. Unlike traditional vision models that rely on labeled images, LVLMs use natural language prompts to detect, describe, and understand objects within an image. This means they can recognize objects that were never explicitly trained into them just by understanding language descriptions.
Think of giving AI a prompt like: “Find the steaming cup of coffee on the table.” A conventional object detector would struggle unless it had been specifically trained to recognize coffee cups. But an LVLM? It can infer from language that a coffee cup is likely to be round, have a handle, and possibly have steam rising from it. That’s the power of combining vision with language.

What is Object Detection with LVLMs?

General framework for Transformer based vision-language models
Traditionally, object detection systems were confined to recognizing a limited set of predefined categories. However, the advent of LVLMs has changed this landscape. By integrating the vast semantic understanding of language models with the perceptual capabilities of vision models, LVLMs enable open-vocabulary object detection. This means systems can now identify and comprehend objects beyond their initial training scope, adapting to novel categories seamlessly.
How LVLMs achieve Pixel-Precise Object Localization
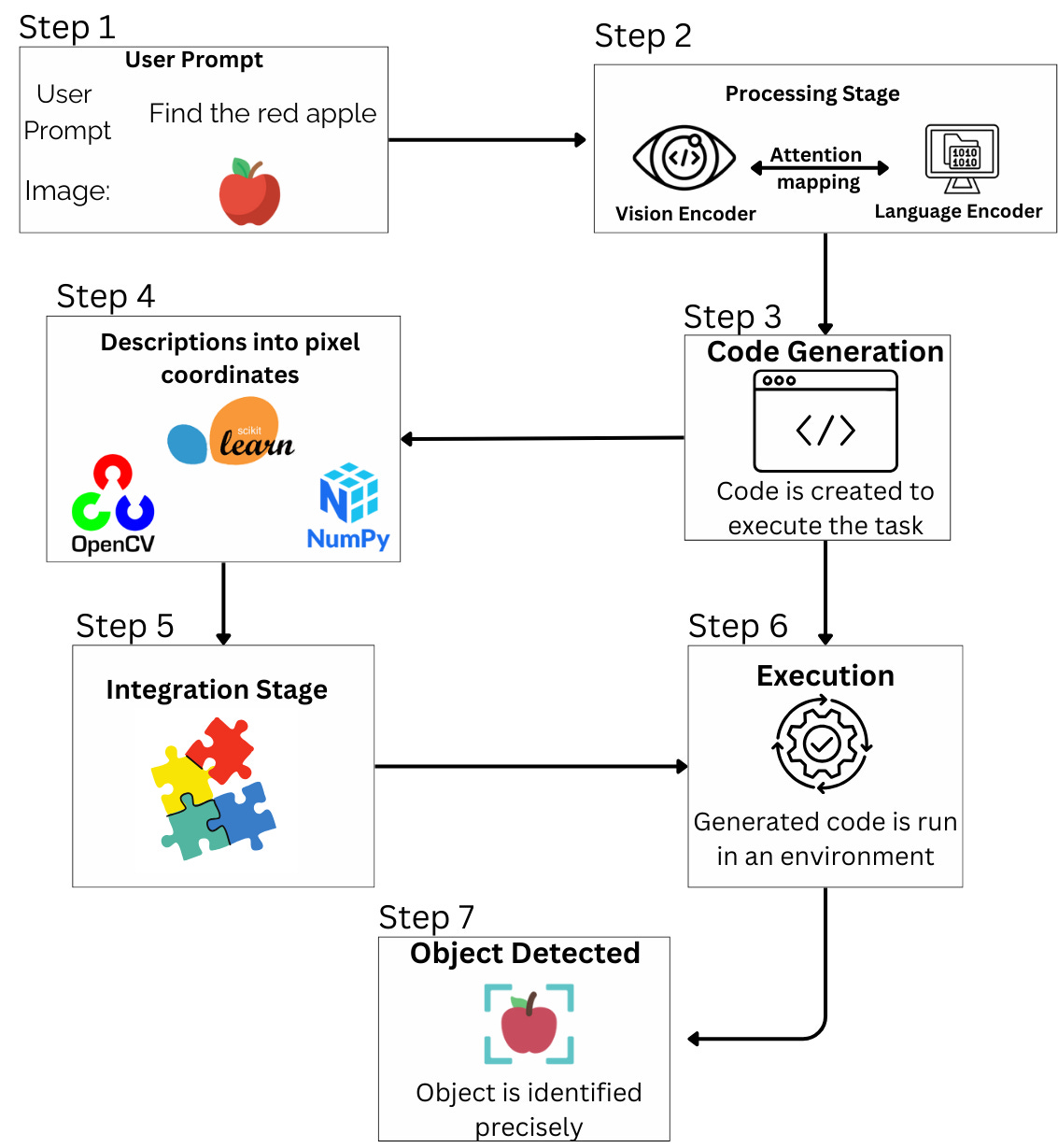
LVLMs don’t just detect objects they can pinpoint exact locations in an image with pixel accuracy. LVLMs enable highly accurate object detection by combining vision processing with natural language understanding. Unlike traditional models, which rely on predefined bounding boxes, LVLMs dynamically interpret user prompts and generate precise object coordinates on the fly.
Step-by-Step Process
User input (Text + Image): A user provides a natural language prompt (e.g., "Find the red apple") along with an image.
Processing stage
→ Vision encoder – Extracts features from the image.
→ Language encoder – Understands the text prompt.
→ Attention mapping – Links words to relevant regions in the image.
Code generation: The LVLM generates executable Python code that tells the AI how to detect and localize the object.
Pixel-Level localization: Using tools like OpenCV, NumPy, and scikit-learn, the AI converts attention maps into precise bounding boxes.
Execution & Object detection: The generated code is executed, and the object is accurately detected and highlighted.
Example: How an LVLM Works in Action
Think of showing an LVLM a random image and asking:

Prompt: "Find the flamingo in this image."
What happens:
Step 1: Processing the Image (Vision Understanding)
First, the LVLM scans the image, much like how our eyes process a scene. Instead of seeing the image as a single picture, the model breaks it down into smaller pieces like patches or grids extracting important features such as colors, textures, edges, and shapes. This step is similar to how traditional computer vision models work, but LVLMs take it further by making sense of objects in a more flexible way.
Step 2: Understanding the Text Prompt (Language Processing)
Next, the model reads and interprets the text prompt. It recognizes the words “Find the flamingo” and understands that it is looking for a specific object in the image. Thanks to its vast knowledge from training on both text and images, it knows that a flamingo is typically pink, has long legs, and a curved neck.
Step 3: Matching Language to Vision (Cross-Modal Alignment)
Now, the real magic happens! The LVLM connects the knowledge it has about flamingos from text with the visual features it has extracted from the image. It searches the image for anything pink, with a tall, slim shape, and possibly a beak.
Traditional object detectors would need a pre-trained dataset with thousands of labeled flamingo images, but LVLMs don’t they infer what a flamingo looks like just from language understanding.
Step 4: Finding the best match (Attention Mechanism)
The model doesn’t look at the entire image at once. Instead, it focuses on the most relevant parts, zooming in on different areas to determine which one best matches the description. This works similarly to how our brains process images when someone tells you to look for a red apple in a fruit basket, you don’t scan every fruit one by one; instead, you immediately focus on anything red.
This attention mechanism allows LVLMs to prioritize the most likely locations of the flamingo without needing exhaustive manual training.
Step 5: Drawing the Bounding Box (Final Detection)
Once the LVLM is confident about the location of the flamingo, it marks it by drawing a bounding box around it. This box highlights the exact position of the object in the image. Unlike traditional models that rely on predefined categories, LVLMs adapt to new and unseen objects dynamically, making them incredibly flexible.
Output: A bounding box is drawn around the flamingo.
Unlike traditional object detectors, the LVLM doesn’t need prior training on flamingos it understands them through its language-vision knowledge.
Technologies behind LVLMs
LVLMs are powered by advanced AI architectures that enable their multimodal capabilities:
Transformer-Based Models: Just like GPT models process text, LVLMs use transformers to handle both text and image inputs, linking words with visual features.
Pre-trained Vision-Language Models: Many LVLMs learn from massive image-text datasets like LAION-5B, OpenAI’s CLIP, or Google’s Flamingo, which allow them to map text descriptions to objects.
Zero-Shot and Few-Shot Learning: LVLMs don’t need extensive fine-tuning for every task. They can recognize new objects dynamically based on their existing knowledge.
LVLMs vs. Traditional Object detection: Trade-offs
LVLMs bring game-changing improvements, but they also introduce new challenges. Here are some key trade-offs:
Latency: LVLMs generate and execute code dynamically, making them slower than traditional models that operate with precomputed detection pipelines.
Prompt Sensitivity: The effectiveness of LVLMs depends on the clarity of the user’s prompt. Vague or ambiguous descriptions can lead to misinterpretations.
Computational Demand: LVLMs require powerful GPUs to function efficiently, making them less accessible for low-power devices.
Interpretability: While traditional models provide fixed, deterministic outputs, LVLMs generate responses dynamically, making debugging and consistency more complex.
Challenges of LVLMs:
Latency is a significant bottleneck in LVLM-based object detection. Unlike conventional object detectors that instantly recognize predefined objects, LVLMs must first interpret the text prompt, extract relevant visual features, generate detection logic, and then execute the localization process. This multi-step approach increases processing time, making LVLMs less suitable for real-time applications like autonomous driving, robotics, or video surveillance, where quick decision-making is essential. Current efforts in optimization techniques such as caching frequently used detection patterns, using smaller fine-tuned versions of LVLMs, and leveraging edge computing aim to reduce inference time. However, achieving near-instantaneous object detection while maintaining high accuracy remains a complex challenge.
Prompt sensitivity is another major limitation, as LVLMs rely on natural language descriptions to guide object detection. The accuracy of their output depends heavily on how well a prompt is phrased. A well-structured request like "Find the red apple on the left side of the table" yields precise results, while an ambiguous prompt such as "Find something interesting in the image" can lead to misinterpretations. Additionally, LVLMs may struggle when multiple objects fit the given description, leading to inconsistencies in detection. Researchers are addressing this issue by refining prompt engineering strategies and incorporating reinforcement learning techniques, such as Reinforcement Learning from Human Feedback (RLHF), to improve the model’s ability to handle vague or contextually complex instructions.
Computational demand remains one of the biggest obstacles to widespread LVLM adoption. These models process vast amounts of multimodal data, requiring high-end hardware like NVIDIA A100, H100 GPUs, or TPUs to operate efficiently. Training LVLMs on massive image-text datasets consumes significant energy and computational resources, making them expensive to deploy at scale. Additionally, running LVLMs on mobile devices or embedded systems is still impractical due to their high memory and processing requirements. Efforts to optimize LVLMs include model compression techniques like quantization, pruning, and distillation, which aim to reduce their size without sacrificing accuracy. Cloud-based deployment is another potential solution, but it introduces trade-offs related to latency, privacy, and accessibility.
Real-World Applications of LVLMs
LVLMs are already transforming industries with their ability to detect objects from natural language prompts.
Retail: Automated stock tracking and smart inventory systems that recognize products based on descriptions.
Manufacturing: AI-driven quality control that detects defects without needing to be reprogrammed.
Healthcare: Medical imaging AI that pinpoints anomalies based on a radiologist’s verbal instructions.
Autonomous Vehicles: Self-driving car AI that detects unexpected obstacles using natural language descriptions.
Final Thoughts: LVLMs - The future is looking right at you !
LVLMs are changing the game in object detection, turning what used to be a painstaking process into an AI-powered, text-to-detection magic trick. No more endless manual labeling, no more rigid models just smart AI that understands what you mean, not just what it was trained on.
Are they perfect? Not yet.
Do they sometimes misinterpret a prompt and label a pineapple as a luxury grenade? Maybe.
But with continuous advancements, LVLMs are on track to change how AI sees and understands the world one object at a time.
Since you read till the end, here’s a meme for you. Enzoi!

Until next time,
Stay curious, stay innovative.