
GPT‑5 Router: A Deep Dive
Understanding GPT-5 Real-Time Routing & Model Orchestration..

The first time I chatted with GPT-5, I realized it wasn’t just answering my questions it was choosing how to answer them. Behind the curtain, GPT-5 runs on a smart “router” that directs each query to the right brain for the job. Quick facts and summaries? The lightweight core model handles those in a snap. Complex reasoning or puzzles? The heavier GPT-5 Thinking model steps in. Need a calculator or external lookup? The router knows when to call a tool.

This shift is big. Instead of being a single, monolithic system, GPT-5 feels like a network of specialists working together with the router as the dispatcher. In todays edition of Where’s The Future in Tech, I’ll explain how that works, why it’s different from earlier models, and what it signals about the next stage of AI design.
Why routing matters now

Let’s be honest: by the time GPT-4 rolled out, we were already seeing a big problem. People used the same gigantic model for everything from writing Shakespearean poetry to checking spelling. That’s like using a rocket engine to toast bread. Sure, it works, but it’s wasteful, expensive, and often overkill.
Enter GPT-5 routing. Instead of firing the full rocket every time, the system has a router that quickly analyzes your request and assigns it to the right pathway:
Simple chit-chat? → Route to a small, fast model.
Complex reasoning? → Route to the big GPT-5 brain.
Math/logic? → Route to a symbolic tool or calculator.
Structured tasks (SQL, APIs)? → Route to a specialized executor.
The 4 pillars of routing
So what does GPT-5 actually look at when deciding which “brain” to spin up? After using it daily and digging into OpenAI’s docs, I’d say it boils down to four main factors: conversation type, task complexity, tool needs, and explicit user intent.
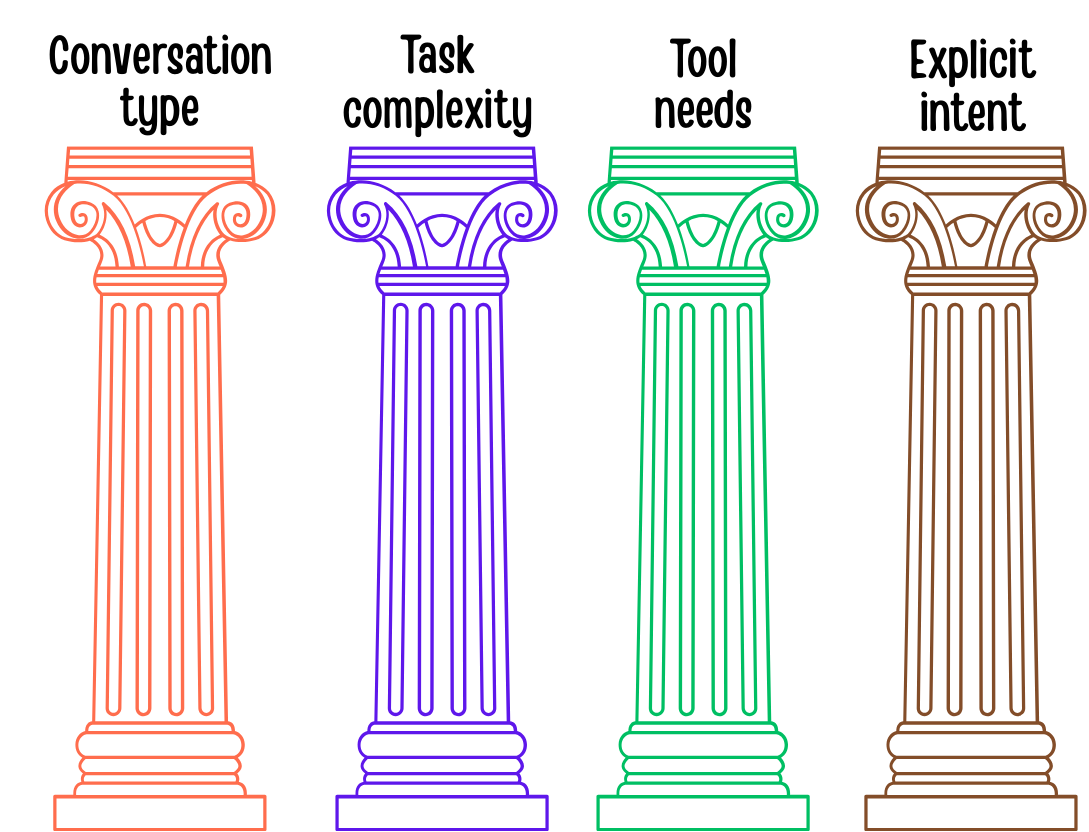
1. Conversation type: Is this just casual chatter, or something more structured like a code review, a math proof, or a story draft? GPT-5 has learned which model handles each best. A quick back-and-forth about weekend plans usually stays in fast mode, while a step-by-step derivation of a theorem reliably triggers thinking mode.
2. Task complexity: If your prompt looks tricky, GPT-5 doesn’t hesitate to bring in its heavyweight reasoning model. In technical terms, the router spots subtle signals of difficulty in your words and allocates the bigger brain. AIMultiple noted that GPT-5 uses a hybrid multi-model system, routing based on prompt complexity and desired speed. Translation: it doesn’t burn cycles on easy stuff, but it also won’t undershoot when you ask for something dense.
3. Tool needs: Mention a task like “calculate,” “look up,” or “draft an email,” and the router knows to bring in a tool-equipped model. Unlike earlier systems where plugins or tool calls had to be explicitly enabled GPT-5 handles this invisibly. If a query clearly benefits from executing code or hitting a database, the router automatically hands it off to the right model. Early testers even found that GPT-5 cut tool-calling errors nearly in half compared to GPT-4, thanks to better routing and specialization.
4. Explicit intent: Sometimes the router simply listens to you. If you write “think hard about this,” it’ll spin up the deep reasoning model. I’ve tested subtle phrasing tweaks like “quickly summarize” versus “deeply analyze” and watched GPT-5 adjust modes on the fly. It’s almost like we’ve unlocked a new “soft instruction” layer, where your wording nudges the router just as much as the hidden heuristics.
A leap beyond Toolformer and Plugins
Some of you might remember Toolformer: a 2023 paper where a language model taught itself, during training, to call external tools via API. Clever, but static: the model learned fixed rules like “use calculator here” from signal tokens in its dataset. Once deployed, it couldn’t adapt beyond what it had memorized.
GPT-5’s router is different. It’s dynamic, making runtime decisions. Instead of parroting a pre-learned “calculator time,” it behaves like a live assistant who hears your question and decides in the moment: “I should grab the calculator now.”
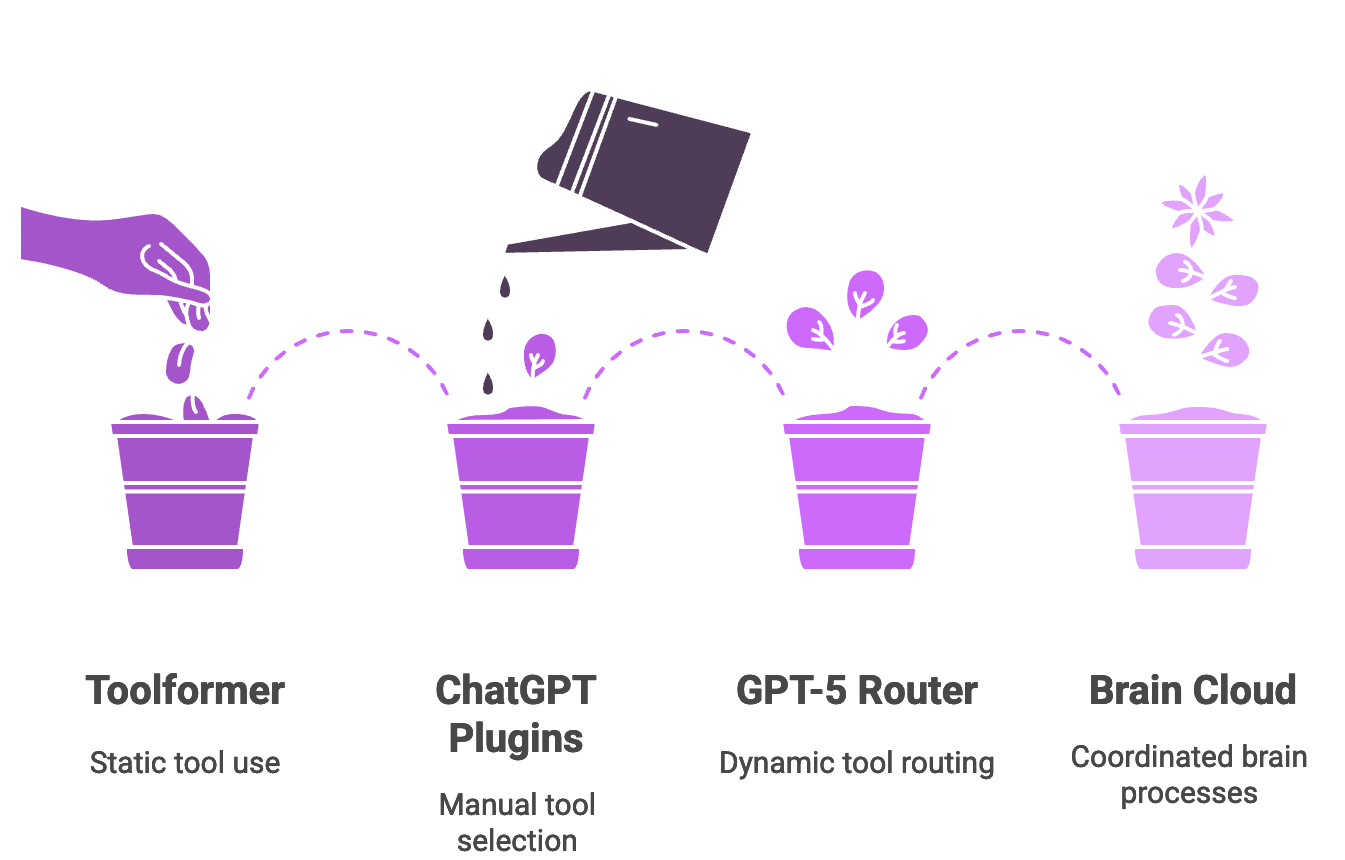
Plugins in ChatGPT had a similar limitation: users had to enable them manually and often say “use Wolfram Alpha for math.” GPT-5 replaces that with a built-in strategy layer. If a query demands tool use, the router simply routes to the right model already connected with those tools. Even custom tools in the new API rollout lean on this routing system in the backend.
In short, GPT-5 blends Toolformer’s self-tool use with plugin ecosystems but adds a real-time traffic cop in the middle. Where GPT-4 felt like a single supercomputer, GPT-5 works more like a cloud of brain processes coordinated by a router. And if you’ve ever debugged microservices, you’ll immediately get why that metaphor sticks.
Building your own GPT-5 style router
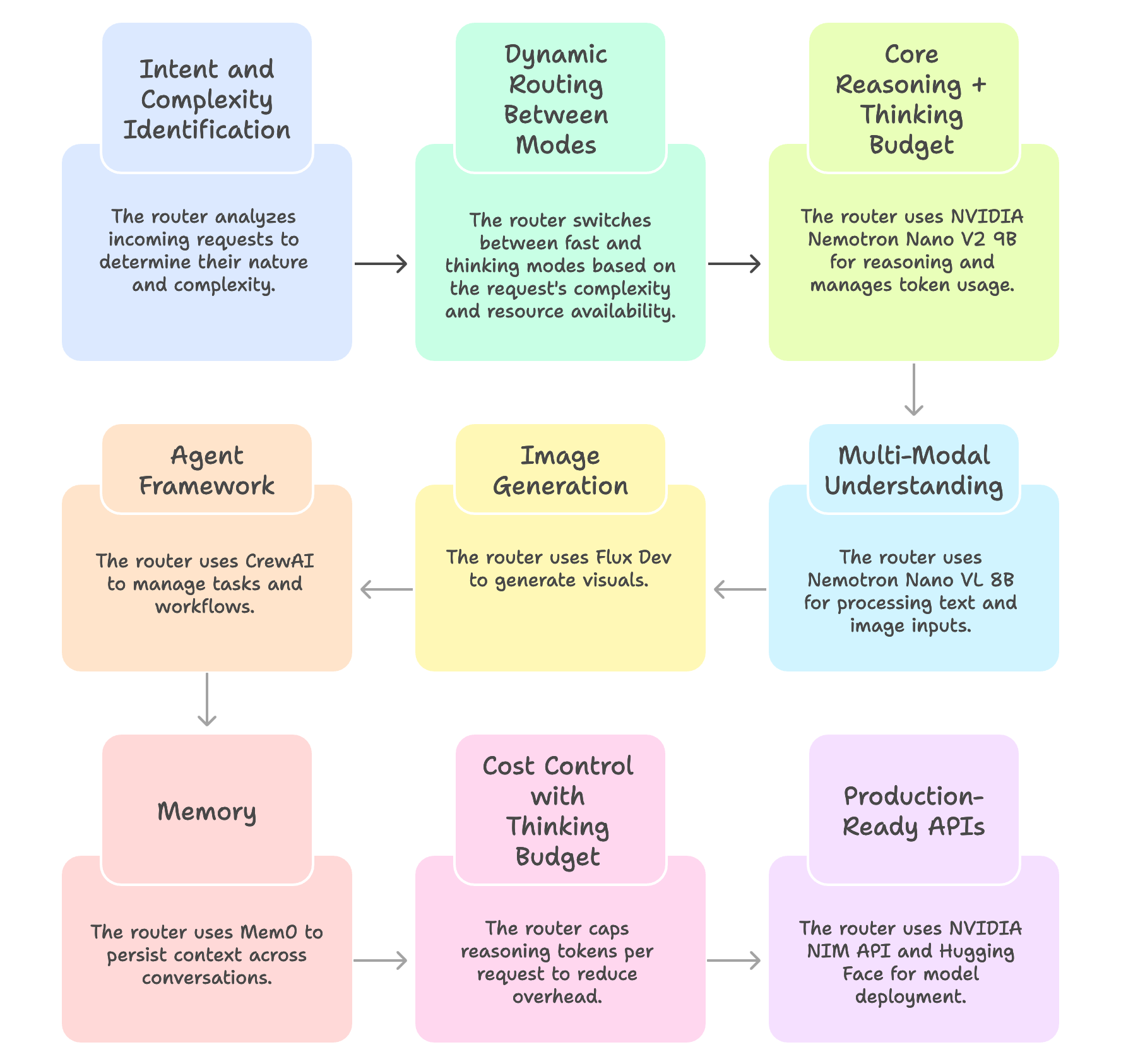
Now, I know what you might be thinking: “Cool story, but how do I actually build something like this myself?” Luckily, you don’t need to be OpenAI with infinite compute to experiment. With today’s open-source ecosystem, you can actually put together a lightweight GPT-5-style router on your own machine. Here’s how one approach works:
1. Intent and Complexity identification: At the core, the router must first understand what kind of request is coming in. Is it a quick fact lookup? A reasoning-heavy math proof? A request for an image? Or maybe a need to browse the web? A lightweight classifier (or even a small LLM) can do this triage step. Think of it as the “air traffic controller” of your AI stack.
2. Dynamic routing between modes: Instead of treating all queries equally, the router intelligently shifts between “fast” and “thinking” modes:
Fast mode – sends the query to a lower-latency model for quick replies.
Thinking mode – unlocks reasoning tokens for deeper logic, trade-off exploration, or multi-step answers.
Fallback mode – if GPU memory is tight, route to a smaller backup model so the system never goes down.
3. The engines under the hood: Here’s one concrete open-source setup that makes this possible:
Core reasoning + Thinking budget → NVIDIA Nemotron Nano V2 9B a hybrid Mamba-Transformer model that runs well on an RTX GPU. It’s fast, accurate, and can throttle token usage.
Multi-modal understanding → Nemotron Nano VL 8B for text + image input.
Image generation → Flux Dev for generating visuals.
Agent framework → CrewAI to manage tasks and workflows.
Memory → Mem0 to persist context across conversations.
This stack alone lets you build a router that feels eerily close to what GPT-5 is doing behind the scenes.
4. Cost Control with a thinking budget: Not every prompt needs “10,000 tokens of thought.” By capping reasoning tokens per request, you can reduce overhead dramatically. Teams experimenting with this approach report up to 60% cost savings because the router only spends compute where it matters.
5. Production-Ready APIs: NVIDIA is already shipping these models via NIM API and Hugging Face. That means you don’t need to train from scratch you can plug these models in today and start experimenting.
Refer my video for demo:
Benefits of the GPT‑5 Router
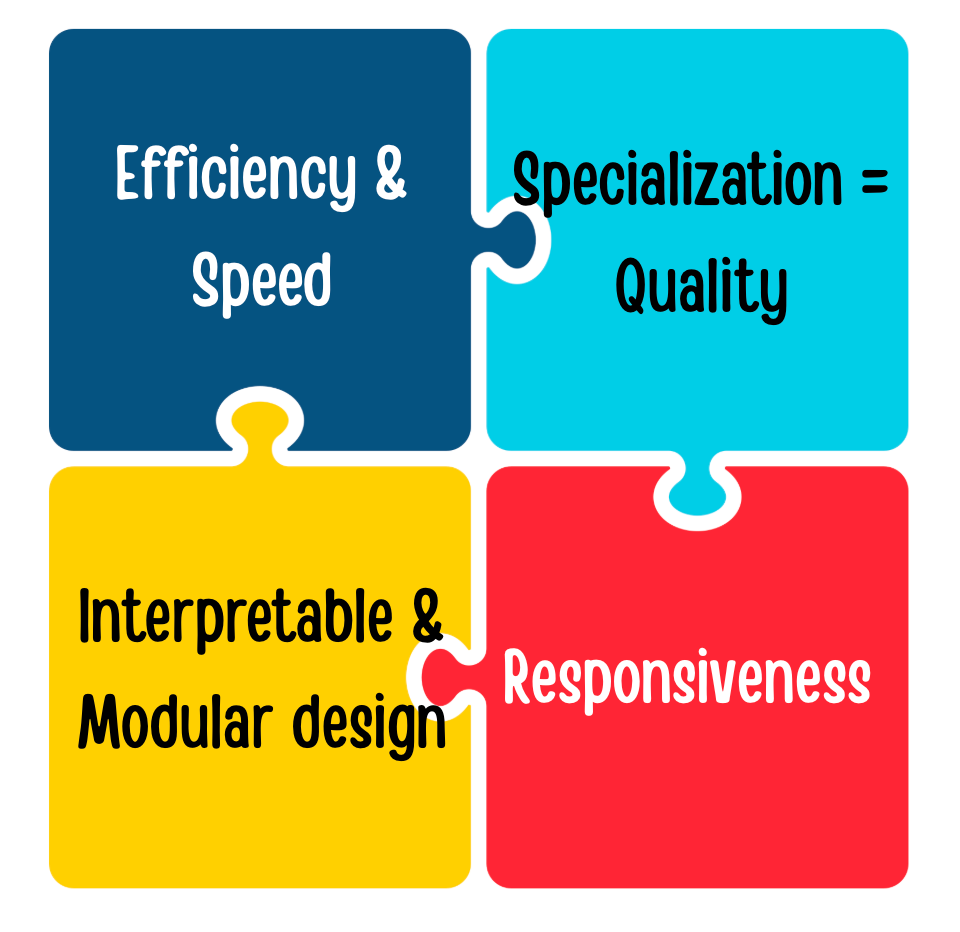
Efficiency & Speed
Most queries default to the faster model, saving compute.
Lightweight tasks no longer run through the deep-reasoning engine.
OpenAI hinted that if the system overloads, a “mini” model can step in for low-stakes queries, keeping things scalable.
Responsiveness
GPT-5 answers “on the fly” for basic questions, often 2–3× faster than GPT-4 Turbo in benchmarks.
Automatic routing means users don’t need to switch models you just get fast answers when speed matters and deeper ones when it counts.
There’s also a manual Fast/Thinking toggle if you want control.
Interpretable & Modular design
Each sub-model has its own specialty and can be improved independently.
Errors are easier to debug: “wrong model picked” vs. “thinker gave a bad answer.”
Think of it like microservices in an AI pipeline modular, clear roles, easier to maintain.
Specialization = Quality
Sub-models are tuned for specific roles: e.g., “thinking” for multi-step reasoning, “main” for brevity and knowledge.
Offers the best of both worlds: GPT-4-level knowledge + GPT-3-level speed.
Can even “switch gears” mid-conversation, e.g., moving from brainstorming text to handling code, without explicit instruction.
Hiccups and Headaches: Limitations
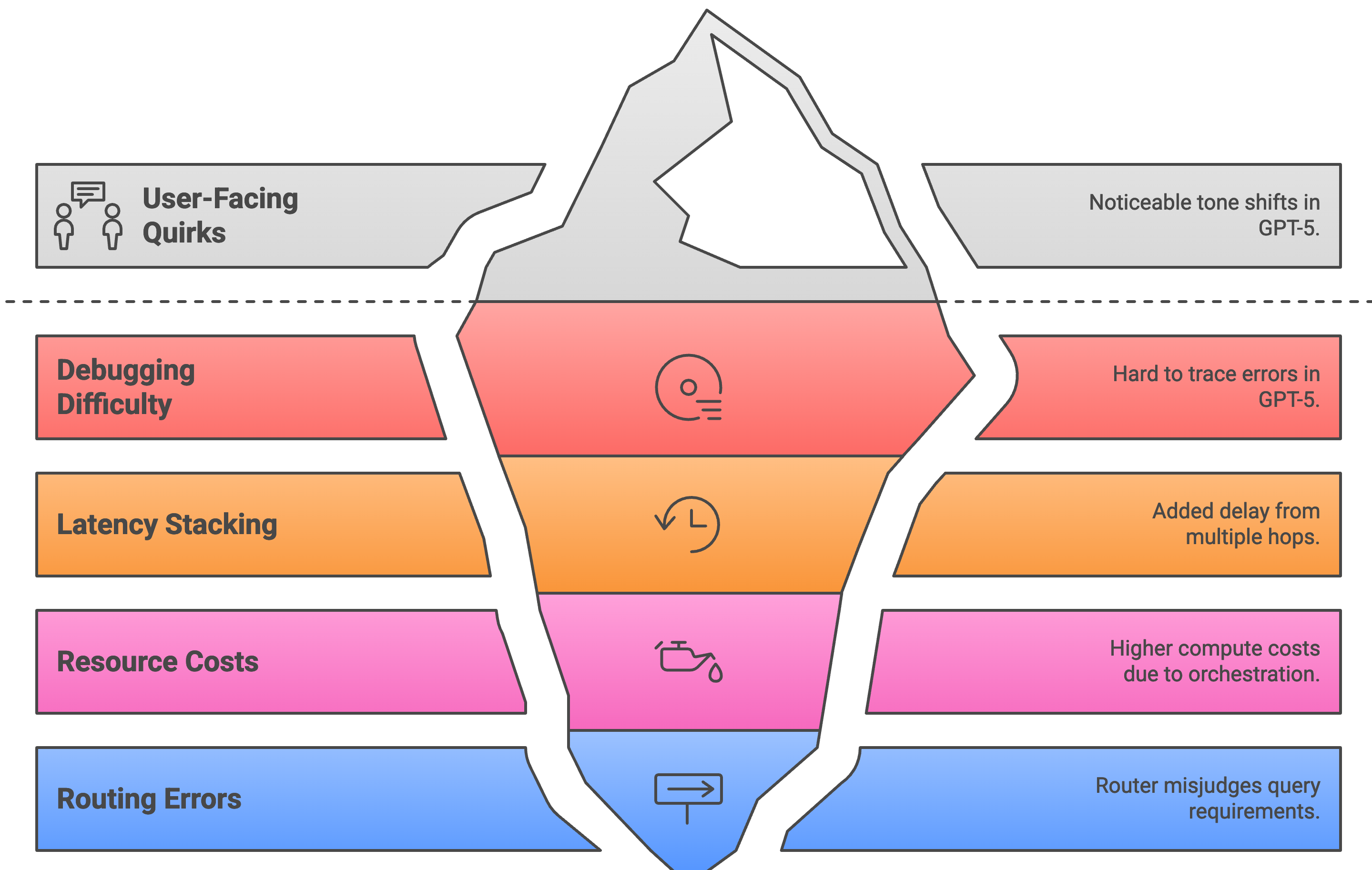
Debugging difficulty
Hard to trace errors: Was it the router picking the wrong model, or the chosen model making a mistake?
More like debugging a distributed system than a single monolith.
Required special tracing tools (inspired by Amazon Bedrock’s frameworks) to log each step: router decisions, tool calls, results, stitched outputs.
Still meant “more moving parts to inspect” whenever something went wrong.
Latency stacking
Each extra “hop” (e.g., main → thinking → math tool → back → final answer) adds delay.
Simple questions usually bypass layers, but complex queries can become noticeably slower.
Amazon’s multi-agent notes warned of this: overhead grows with serial reasoning chains.
Mitigation: parallelizing calls + caching results, though multi-tool workflows sometimes ended up slower than a single GPT-4 call.
Resource costs
Multiple small models can sometimes burn more compute than one large model.
Router thresholds had to be tuned so borderline tasks went to the faster model.
Independent analyses found ChatGPT-5 occasionally used double the tokens per query vs GPT-4, due to orchestration overhead.
Even OpenAI acknowledged GPT-5 could be “more compute-intensive” despite efficiency goals.
Trade-off: smarter allocation vs higher system complexity.
User-Facing quirks
Some users noticed tone shifts GPT-5-thinking (formal, reasoning-heavy) vs GPT-5-main (more natural).
Personality filters were added to keep the chatbot feeling like “one voice.”
Without tuning, it could feel like multiple AIs with slightly different styles in one conversation.
As one quip went: “GPT-5’s brain may be clever, but it can suffer identity crises.”
Routing errors
Router sometimes misjudges: picking “fast” when the query needed “deep,” or vice versa.
Monitored through “model switch” events (when users regenerate an answer).
Not foolproof: fallback is user hitting “Regenerate,” hoping the other model is chosen.
Each switch means reloading a fresh static prompt adding latency and token costs.
In practice, mid-answer gear switches ate into the “smooth conversation” experience.
What this means for AI’s future
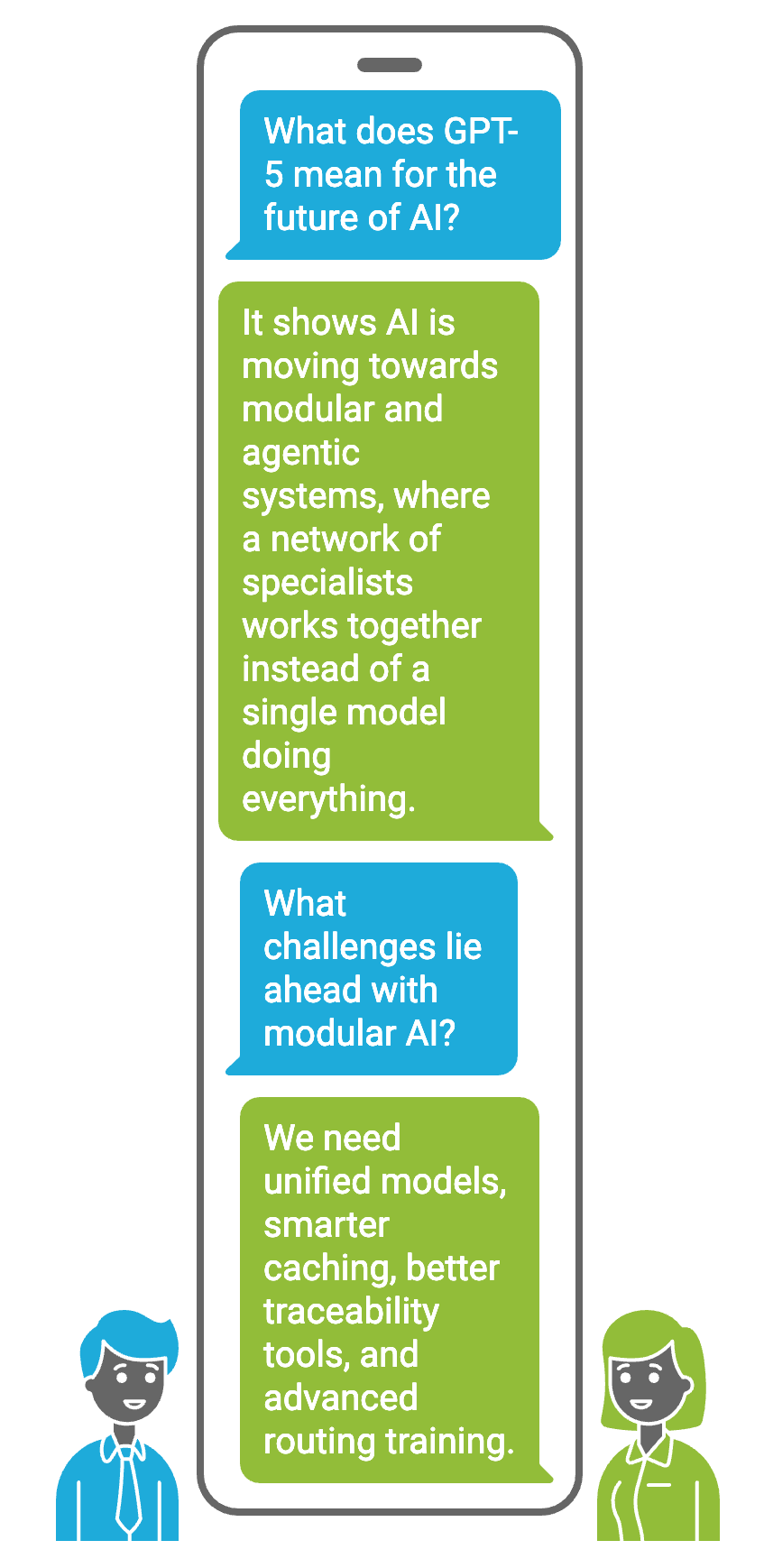
GPT-5’s router+models setup tells a bigger story: AI is moving beyond one-size-fits-all models. Researchers have long discussed modular and agentic AI, and GPT-5 is one of the clearest proofs that this shift is happening. As one analysis put it, GPT-5’s “multi-agent architecture (router + models) hints at how we might design modular AI systems that overcome single-model limitations.” In plain terms, it shows you can build an LLM system as a network of specialists rather than relying on a single genius.
Future AI will likely become more agentic models working together instead of one doing it all. We may soon see even more fine-grained experts (some labs are already testing “100-expert LLMs”) coordinated by a central controller. GPT-5 proves that coordination overhead can be worth it, especially as hardware keeps accelerating. Don’t be surprised if GPT-6 or Gemini Next ships with a supercharged router managing dozens of sub-models or if plugins evolve into autonomous “agents” summoned by a metamodel.
The challenges ahead
Of course, modularity isn’t free. GPT-5 highlights challenges we’ll need to solve:
Unified models to eventually merge specialized roles into one brain.
Smarter caching so routing doesn’t carry static-prompt overhead.
Better traceability tools for debugging multi-agent dialogues.
Advanced routing training (perhaps reinforcement learning) so the router learns truly optimal policies.
The bigger picture
Still, GPT-5’s design makes one thing clear: modularity is here to stay. The architecture mirrors how humans organize knowledge as specialized teams of experts and now AI is catching up.
Final thoughts
After months with GPT-5, I’m both excited and humbled. The real-time router has turned the model from a lone “genius” into a collective of specialists. That brings efficiency and power, but also the challenge of keeping this distributed system in sync. Some days it feels like conducting an orchestra: the fast violins, the deep-thinking brass, all needing harmony.
What excites me most is that GPT-5 proves AI doesn’t need to be monolithic. We can have on-demand specialization, with the system learning how to learn and adjusting its strategy per query. As a developer, I’ve even learned how to “speak to the router” nudging it with prompts like “Auto mode” or “Fast.” Looking ahead, I wouldn’t be surprised if GPT-6 feels more like a “society of minds.” For now, though, GPT-5’s router is a fascinating milestone and one I’m glad I got to explore.
![30+ ChatGPT Memes Madness [Not generated by ChatGPT 🤣] | Engati](https://substackcdn.com/image/fetch/$s_!nM7-!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Ff5847e63-ed4a-4e76-a50f-f172cf4db280_576x500.jpeg "30+ ChatGPT Memes Madness [Not generated by ChatGPT 🤣] | Engati")
Until next time,
Stay curious, stay innovative and subscribe to us to get more such informative newsletters.