


💸 Clever Ways to Lower Your LLM Costs in 2025 (Without Breaking Performance) - Part 1
You’re Not Broke, Your LLM Is Just Lazy!

Large language models are brilliant. But they’re also resource-hungry divas that chew through GPUs, tokens, and cloud credits like there’s no tomorrow.
You don’t need a smaller wallet.
You need a smarter stack.
In todays’ edition of Where’s The Future in Tech, I’m walking you through some strategies I’ve personally used to slash LLM costs without sacrificing quality, speed, or scale. No vague tips. No surface-level theory. Just real methods that work in production.

Whether you're fine-tuning on a budget, scaling inference to thousands of users, or deploying to edge devices, this guide’s got something to save your sanity (and your cloud bill).
1. LoRA (Low-Rank Adaptation)
You want to fine-tune a 7B or 13B parameter LLM for a downstream task (e.g., summarizing legal contracts). But updating billions of parameters is expensive, slow, and takes tons of VRAM. You also don’t want to maintain a separate fine-tuned model copy per task it’s a storage nightmare.

An illustration of LoRA architecture
The Core Idea
LoRA introduces two small trainable matrices per target weight matrix, which approximate the weight updates that would’ve happened during full fine-tuning.
So instead of updating the full 4096×4096 matrix in a transformer layer, you update two much smaller ones:
One with shape
[r × d]One with shape
[d × r]
Wherer(rank) is very small (e.g., 4 or 8)
The full weight becomes:
W' = W + ΔW
= W + (A @ B)Where W is frozen, and A (down projection) and B (up projection) are the trainable parameters.
This keeps ΔW in a low-dimensional subspace hence “low-rank.”
What Layers Are Modified?
Usually:
The query and value projection matrices in the attention mechanism (because they’re task-sensitive)
Sometimes, the feed-forward network (FFN) layers
You don't touch the full model. Just add these LoRA modules and train them.
Trade-Offs
LoRA doesn't always outperform full fine-tuning (especially for domain adaptation with lots of data)
If your task requires re-learning core knowledge (not just task-specific tuning), LoRA may underfit
Need proper rank selection too small and it bottlenecks expressiveness
When to Use
You want to customize a foundation model for multiple tasks (chat, summarization, extraction) with minimal infra
You’re running training on limited GPUs
You need to deploy on-demand per user/task with fast switching (load adapters dynamically)
Companies like Hugging Face, Stability AI, and even Meta are using LoRA for:
Serving domain-specific LLMs in healthcare/finance without retraining full models
Open-source LoRA adapters (like Alpaca) for cheap fine-tunes on GPT models\
2. Model Quantization – Making Your LLM Lightweight and Fast
So I’m sitting there, watching my 13B model crawl through inference like it’s sipping molasses. GPU memory is maxed out, latency is through the roof, and the cloud bill is laughing in my face. That’s when I realized I don’t need perfect precision for most tasks. I just need something good enough, fast.

What It Actually Does (No Jargon)
Quantization is about using smaller numbers to represent your model weights and activations.
Normally, models use 32-bit floating-point (FP32) numbers. But let’s be honest does a difference at the 11th decimal place really matter when you’re generating a tweet summary? Not always.
So instead, we say: “Hey model, use 8-bit integers (INT8).” Or even 4-bit floats. Now your tensors shrink by 75–90%. Computation gets faster, cheaper, and less memory-hungry.
Here’s the simplified view:
The model has weights like:
[0.2451234, -1.2439823, 3.2348123, ...]Quantization maps those to 256 possible values (in INT8):
[-128, -127, ..., 0, ..., +127]The real values are reconstructed like:
dequantized = scale_factor * int8_value + zero_pointSo it’s reversible, but approximate. You trade precision for efficiency.
Two Main Flavors
Post-Training quantization (PTQ)
Super easy. You take a trained model and convert the weights to INT8 using a calibration dataset. Fast, but accuracy may drop if the data distribution shifts.Quantization-Aware training (QAT)
You simulate quantization during training. Slower to train, but you bake in the approximations so the model learns to live with low precision. Results are much better.
Quantization isn’t just about saving disk space:
8-bit inference = 2–4x speedup
Up to 75% memory savings
Lower power consumption on GPU/TPU
Can now run a 13B model on a consumer GPU (like RTX 4090 or even Apple M2 with CoreML)
Trade-offs and Gotchas
Accuracy hit: In PTQ, expect 1–2% accuracy drop (more for classification than generation)
Not all layers quantize well: LayerNorm and Softmax are sensitive sometimes left in FP16
Hardware support varies: You need inference engines like TensorRT, ONNX Runtime, or PyTorch 2.0 that can exploit INT8 cores
3. Pipeline Parallelism – Turning Your Model Into an Assembly Line
I had this chunky 13B model. Worked great. Until... I tried training it. One GPU wasn't enough. I’d get out-of-memory errors before I even started. Splitting the model across GPUs seemed like the obvious answer, but plain-old data parallelism just cloned the model on each GPU not helpful when the model doesn’t even fit once.
That’s when I found pipeline parallelism.
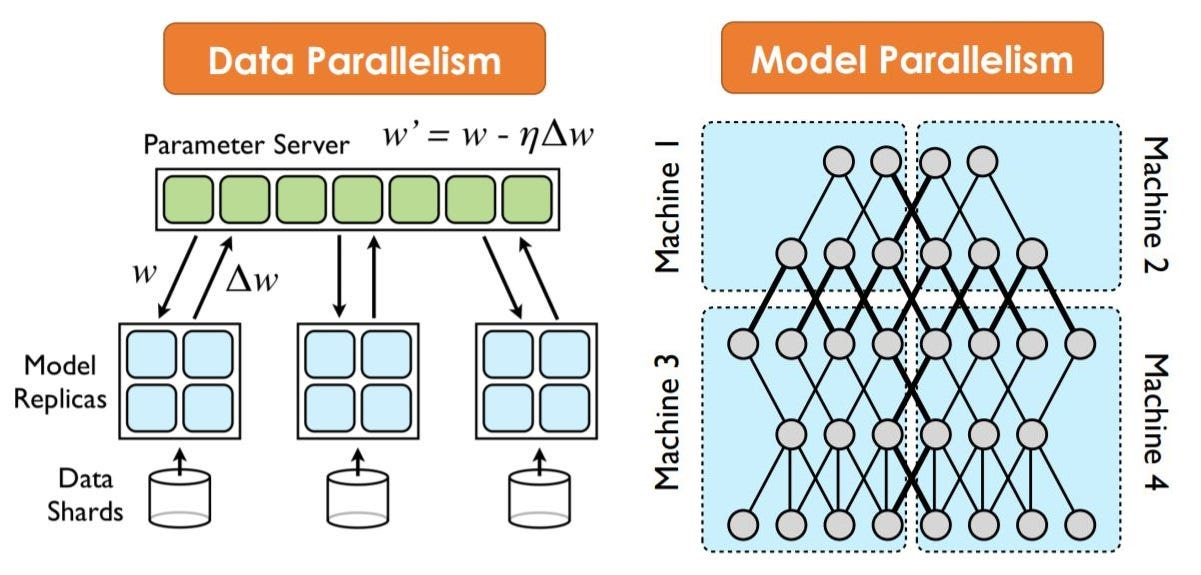
Data parallelism and Model parallelism
What Is Pipeline Parallelism (Really)
It’s exactly what it sounds like: turning your model into a pipeline, where each stage of the model lives on a different GPU.
Think of your transformer like this:
[Layer 1] → [Layer 2] → [Layer 3] → ... → [Layer N]With pipeline parallelism, it’s split:
GPU 0 → Layers 1–4
GPU 1 → Layers 5–8
GPU 2 → Layers 9–12 Each GPU works on its stage, passing intermediate outputs to the next GPU.
Why It’s Brilliant
Instead of needing one massive GPU to hold the whole model in memory, you spread the model across multiple GPUs, each handling a slice of the computation.
And here's the real kicker: once stage 1 finishes a forward pass for batch 1, it immediately starts working on batch 2, while stage 2 is processing batch 1.
Like a production line.
→ Parallelism over time.
Real Performance Gains
Cuts VRAM needs per GPU by 50–75%
Lets you train or infer with larger models on commodity hardware
Works really well with long context LLMs (since early layers do less heavy lifting)
Trade-Offs I Had to Deal With
Bubble overhead: the pipeline can’t be fully utilized until all stages have data flowing (you lose some efficiency at the start & end of runs)
Latency: not great for single-query inference; better for training or batch mode
Load imbalance: if one GPU gets a heavier slice, it becomes the bottleneck
To fix load imbalance, I sometimes do custom slicing:
# Heavier layers go solo on one GPU
GPU 0 → Layers 1–2
GPU 1 → Layer 3 (big!)
GPU 2 → Layers 4–6 Combining with Other Tricks
Pipeline parallelism pairs beautifully with:
Data parallelism: for training multiple copies of the pipeline on different data
Tensor parallelism: slicing individual matrix multiplications across GPUs (e.g., Megatron-LM style)
Activation checkpointing: to save even more memory
Use pipeline parallelism when:
The model is too large for a single GPU
You have multiple GPUs but limited memory per GPU
You want to train large models without going broke renting A100s
4. Fine-Tuning
I had a general-purpose LLM. Worked fine for generic tasks. But when I asked it to write investment risk assessments or extract biomedical terms from research papers?
Total hallucination city.
So I needed a way to make the model smarter for my domain, without retraining it from scratch. That’s when I leaned into fine-tuning but the right kind of fine-tuning.

At its core, fine-tuning is taking a pre-trained model and training it just a bit more on new, task-specific data.
You’re not teaching the model everything from scratch. You're saying:
“Hey GPT, you already know English. Now let me show you how we talk in legal contracts or clinical notes or e-commerce support tickets.”
This adjustment teaches the model the nuances of your domain while keeping the vast general knowledge intact.
Smart Fine-Tuning: My Real Strategy
Instead of fine-tuning all 7B parameters (super expensive), I usually:
Use LoRA + Fine-tuning
Combine fine-tuning with parameter-efficient tuning:
Freeze 99% of the model
Only train small adapter modules
Freeze most layers:
Fine-tune only the top few layers
Use smaller models for task-specific roles
If all I need is a classifier or summarizer, I’ll distill or use smaller LLMs (like Mistral or Falcon-1B) and fine-tune those instead.
What It’s Good For
Instruction tuning (e.g., teach the model to follow custom prompts)
Domain adaptation (legal, medical, scientific)
Style control (corporate tone, emojis, multilingual tone)
Task-specific behavior (chatbots, extractors, rerankers)
Gotchas
Overfitting is easy if your dataset is small. I use early stopping and eval metrics obsessively.
Forgetfulness: Full fine-tuning can cause catastrophic forgetting (model loses pre-trained knowledge). That’s why LoRA or partial layer training is usually better.
Needs proper tokenization & alignment between inputs and outputs.
5. Data Optimization
I once ran a fine-tuning job on 200k customer reviews for an e-commerce client. Took forever, and the results were… meh. Turns out, half the data was:
Duplicated
Full of typos
Irrelevant to the task
That’s when I learned: good data beats more data.

Dynamic data transformation for read-optimization: architecture overview
It’s not just “cleaning” data. It’s about curating the right data, in the right form, with just the right amount of diversity and structure.
Because with LLMs, every useless token:
Bloats training time
Wastes GPU cycles
Harms convergence
Kills output quality
In short: it burns money.
What I Do Step-by-Step
Here’s my real-world data optimization process before fine-tuning or training any LLM:
1. Deduplication
If the same sentence or paragraph shows up multiple times, the model overfits to it. I use this to detect and remove:
import requests
import pdfplumber
from datasketch import MinHash, MinHashLSH
import re
# Step 1: Download the PDF
def download_pdf(url, filename="temp.pdf"):
response = requests.get(url)
with open(filename, 'wb') as f:
f.write(response.content)
return filename
# Step 2: Extract text from PDF
def extract_text_from_pdf(filepath):
full_text = []
with pdfplumber.open(filepath) as pdf:
for page in pdf.pages:
text = page.extract_text()
if text:
full_text.append(text)
return "\n".join(full_text)
# Step 3: Preprocess and chunk
def split_into_chunks(text, min_len=20):
chunks = [p.strip() for p in text.split('\n') if len(p.strip()) > min_len]
return chunks
# Step 4: Hashing function
def hash_text(text):
tokens = re.findall(r'\w+', text.lower())
m = MinHash(num_perm=128)
for token in tokens:
m.update(token.encode('utf8'))
return m
# Step 5: LSH setup
def deduplicate_chunks(chunks, threshold=0.9):
lsh = MinHashLSH(threshold=threshold, num_perm=128)
minhashes = []
for i, chunk in enumerate(chunks):
m = hash_text(chunk)
lsh.insert(f"chunk_{i}", m)
minhashes.append((f"chunk_{i}", m))
return lsh, minhashes
# Example usage:
pdf_url = "https://arxiv.org/pdf/2302.05894.pdf"
pdf_file = download_pdf(pdf_url)
text = extract_text_from_pdf(pdf_file)
chunks = split_into_chunks(text)
lsh, minhashes = deduplicate_chunks(chunks)
# Find duplicates of the first chunk
query_result = lsh.query(minhashes[0][1])
print(f"Near-duplicates of chunk 0: {query_result}")I usually kill off anything with >90% similarity.
2. Filtering Low-Quality Examples
You’d be surprised how many training examples are junk:
Irrelevant or broken sentences
Mismatched instruction/output
Offensive language (when it shouldn’t be there)
I write filtering rules like:
Minimum token length
No malformed JSON
No repeated outputs like
"Hello! Hello! Hello!"
Or use ML filters like Cleanlab to remove mislabeled examples.
3. Balancing the Dataset
Let’s say you’re fine-tuning a classifier and 90% of your data is “positive” sentiment. Guess what your model learns to do? Spam “positive” for every input.
So I make sure:
The label distribution is balanced
Each prompt type or instruction format appears enough times
4. Augmentation (When Data is Sparse)
Sometimes you don’t have enough data. That’s when I go for:
Paraphrasing (using a base LLM or
nlpaug)Back-translation (EN → DE → EN)
Synthetic examples (generate 100 extra prompt-completion pairs)
Yes, this costs tokens, but it’s worth it if you do it once and train efficiently later.
5. Instruction Normalization
If your instruction formats vary wildly like this:
Prompt: Can you summarize this?
Prompt: TL;DR please?
Prompt: Give me a short summary.So I normalize my prompts with templating or pattern matching to standardize inputs. This improves generalization and lowers convergence time.
When I Always Do This
Before any fine-tuning or distillation
When using scraped or user-generated content (e.g., Reddit, forums)
For domain-specific tasks like code generation, financial Q&A
Tools That Help
clean-text for normalization
snorkel for weak supervision / labeling
langchain + prompts to generate synthetic examples
Google’s deduper (internal, but similar open-source tools exist)
6. Pruning – Trimming the Fat Off Your Model
At some point, I realized: not every neuron in my model was doing useful work. Especially in older, over-parameterized models like BERT-large or even vanilla LLaMA. Many of those weights just sat there… dormant. And yet I was still paying for them in memory, compute, and latency.
")
What Pruning Actually Does
You literally remove parts of the neural network neurons, attention heads, or even entire layers that contribute little to the model’s final output.
There are two main types:
Unstructured pruning: Removes individual weights (sparse matrix)
Structured pruning: Removes entire channels, heads, or layers (preferred for real-world speedup)
The model becomes leaner and inference becomes cheaper.
Let’s say I have a dense layer with 1024 neurons, and I want to keep only the most important 768.
Train the full model
Rank parameters based on weight magnitude or gradient
Drop the lowest-scoring ones
Retrain (or fine-tune) to recover lost accuracy
For structured pruning, I go deeper with custom head or channel masks in attention layers.
Gains
Reduce model size by up to 90%
Run faster on CPU (especially if structured)
Combine with quantization for even leaner models
Gotchas
Unstructured pruning doesn’t always speed things up unless the backend is optimized for sparse ops
Prune too aggressively = massive accuracy drop
Pruning needs retraining to regain quality
7. Multi-Tenancy – One Model to Serve Them All
Why I Switched to Multi-Tenant Architecture
Running a separate model instance for each client or use case? My infra bill ballooned. Plus, spinning up new containers for each user added seconds of cold start latency.
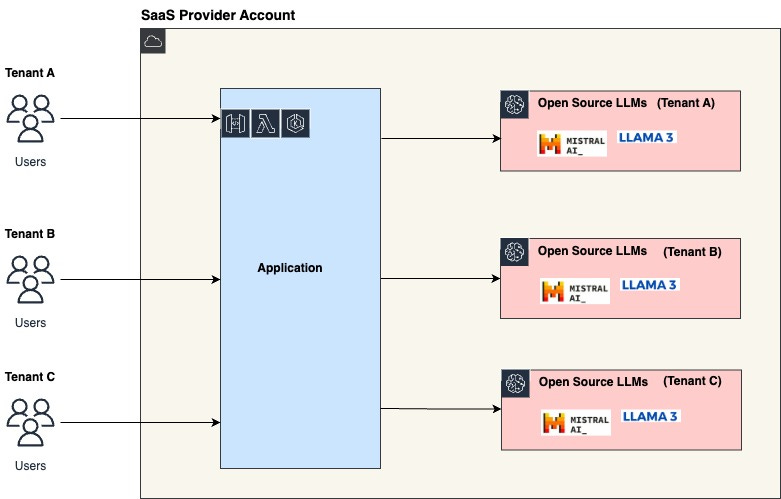
LLMs per tenant (in customer’s environment)
You host a shared model process and route requests from multiple users into it. Your job is to:
Manage request queues
Track which response belongs to which user
Isolate sensitive data per session
Under the hood, the same LLM instance serves all of them.
Tech Stacks
Serving: TorchServe, vLLM, or Hugging Face Inference Endpoint
Queueing: Redis + Celery or FastAPI’s async workers
Load balancing: Kubernetes with horizontal pod autoscaling
Cost Wins
Instead of 10 model containers → 1 shared instance
5–10× reduction in GPU footprint
Easier cache sharing across similar prompts
Trade-offs
Need to handle isolation properly (don’t leak context!)
Heavy request spikes from one tenant can throttle others
Requires tight orchestration
Wrapping Up: It's Not About Spending Less, It's About Spending Smart
Large language models don’t have to be money pits. The truth is, most LLM cost bloat comes from inefficiencies over-provisioned models, sloppy data pipelines, poorly structured prompts, and underutilized infrastructure.
What I’ve shared here isn’t theory it’s a practical, hands-on blueprint that’s helped me and countless teams scale smarter. Whether you're shipping a chatbot, fine-tuning for niche domains, or deploying to mobile, these techniques can save you thousands in compute, hours in latency, and a mountain of engineering debt.
Until next time,
Stay curious, stay innovative and subscribe to us to get more such informative newsletters