
CI/CD for LLM Apps: How to Deploy Without Breaking Everything
Building LLM Apps is Hard, Deploying Them Shouldn’t Be 🚀

Deploying an LLM app isn’t just about writing code and pushing it live. It’s about managing a constantly evolving model, tracking changes in prompts and datasets, and ensuring nothing breaks in production all while keeping costs in check.
When I first started working on LLM deployments, I quickly realized that traditional CI/CD pipelines don’t cut it. Sure, they work fine for web apps, but an LLM-powered app? That’s a whole different challenge.
A small model update might introduce biases, degrade performance, or slow down response times, making it essential to build a CI/CD pipeline that continuously integrates, evaluates, and deploys models safely.

In today’s guide of What’s The Future in Tech newsletter I will take you through the entire CI/CD process for LLM applications, covering:
How LLM deployment differs from traditional software deployment
A detailed breakdown of a CI/CD pipeline architecture for LLMs
Best practices for versioning, evaluation, and deployment strategies
Techniques to optimize model inference and prevent drift
By the end of this, you will have a clear roadmap for automating and scaling LLM deployment while maintaining reliability and efficiency.
Why CI/CD for LLMs is Different

CI/CD pipeline with Github actions
The primary difference between deploying LLM applications and traditional software lies in what is being deployed. A regular software deployment involves updating source code, running unit tests, and pushing changes to production. However, in an LLM-powered system, there are multiple evolving components:
Model weights & versions: Every update might involve fine-tuning an LLM, training a smaller distilled model, or adjusting hyperparameters. Unlike code, models are large binary files that require efficient versioning and storage solutions.
Prompt engineering & configuration changes: Even if the model remains unchanged, prompt modifications can drastically alter its behavior. Testing prompt updates before deployment is crucial.
Retrieval-Augmented Generation (RAG) pipelines: Many LLM applications use vector databases to fetch relevant information before generating responses. Changes in embedding models or indexing strategies need to be validated for accuracy and efficiency.
Inference optimization & cost management: Running LLMs in production is expensive. Quantization, caching, and batching strategies must be tested and deployed carefully to balance performance and cost.
Hallucination & Bias monitoring: Unlike traditional bugs that cause software to crash, LLMs introduce subtle errors like misinformation, bias, or hallucination. Continuous evaluation is necessary to ensure reliability.
Each of these components requires a separate layer of testing and validation before deployment. This is where a well-designed CI/CD pipeline comes in.
CI/CD Architecture for LLM Applications
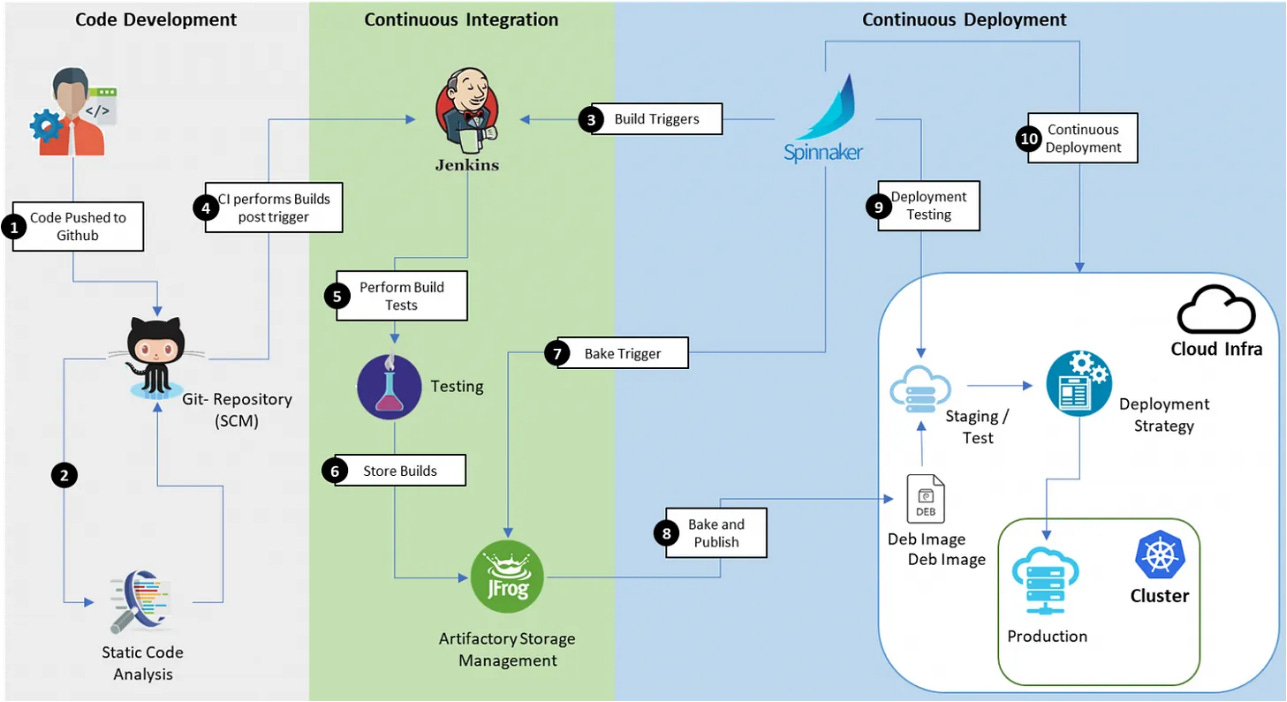
Components of a CI/CD Pipeline
1. Continuous Integration (CI)
The first step in the pipeline is integrating new changes whether it’s an updated model, refined prompts, or optimized pre/post-processing logic. This process must be automated to ensure consistency and prevent regressions.

Version Control for code and models
Unlike traditional software where Git handles versioning, LLM applications require a model registry to store and track different model versions. Tools like Hugging Face Hub, MLflow, or Weights & Biases can be used to maintain a history of model checkpoints and metadata.
It’s important to treat model weights like code ensuring every update is properly tagged and linked to its corresponding dataset, training configuration, and evaluation metrics.
Automated Testing & Benchmarking
Regular software testing involves unit and integration tests, but LLMs require a different set of evaluations:
Functional testing: Ensures the model produces expected outputs for standard inputs.
Benchmark evaluation: Runs the model against predefined datasets to measure accuracy (e.g., BLEU, ROUGE, perplexity).
Bias & Hallucination detection: Evaluates whether the model is generating misleading or biased responses.
Latency & Performance checks: Measures inference time to prevent performance degradation in production.
These evaluations must be automated using continuous testing frameworks, such as Maxim or Promptfoo, which allow you to run LLM-generated responses against test cases dynamically.
Data Validation & Drift detection
Since LLMs are heavily dependent on data, dataset validation is crucial. Incoming data should be checked for:
Schema consistency (e.g., ensuring expected fields are present).
Distribution shifts (e.g., detecting if user queries have changed significantly over time).
Bias detection (e.g., ensuring datasets don’t reinforce unwanted stereotypes).
Tools like Evidently AI help track data drift and ensure models are retrained with fresh, balanced datasets.
2. Continuous Deployment (CD)
Once a model update passes integration tests, it must be deployed without disrupting the user experience. Unlike regular software deployment, where rolling out a new version is relatively straightforward, LLM deployment must consider gradual rollout strategies, cost optimizations, and rollback mechanisms.

Model Deployment strategies
There are multiple ways to deploy an updated model:
Canary deployment: A new model is tested with a small percentage of users before full deployment. If it performs well, it gradually replaces the old version.
Shadow deployment: The new model runs alongside the old one without serving real users. This allows side-by-side performance comparison before rollout.
Blue-Green deployment: Both the old and new models are deployed in parallel, allowing for quick rollback if issues arise.
A/B testing: The new model is exposed to a segment of users while the old model remains in use for the rest. This helps compare real-world performance.
For efficient inference, models should be loaded dynamically based on demand rather than kept in memory persistently. Techniques like quantization (GPTQ, GGML) and distillation can help reduce model size and improve response times.
Deployment tools:
KServe (Kubeflow Serving): Scales model inference dynamically in Kubernetes environments.
Seldon Core: Allows production-scale ML model deployment with rollback capabilities.
BentoML: Provides microservice-based model packaging for lightweight deployment.
3. Continuous Monitoring & Feedback Loops
LLM performance is not static it changes over time due to data drift, evolving user behavior, and new training data. A robust CI/CD pipeline must include real-time monitoring to detect anomalies and enable rapid adjustments.
Key Monitoring Metrics
Inference latency: Measures how long a model takes to generate a response. Slowdowns could indicate server load issues or inefficient caching.
Drift detection: Compares new user inputs against previous patterns to detect significant distribution shifts.
User Feedback integration: Allows users to flag incorrect or biased responses, feeding the data back for model retraining.
Error Logging & tracing: Captures unexpected behavior to diagnose model failures quickly.
Tools like Prometheus + Grafana can be used for real-time monitoring, while OpenTelemetry provides detailed request tracing to diagnose API slowdowns.
Best Practices for CI/CD in LLM Apps
Implementing CI/CD for LLM applications isn’t as simple as setting up a standard pipeline for a web app. The unique nature of LLMs where code, data, and model behavior are all interdependent demands a more nuanced approach. A small tweak in your dataset, a change in prompt phrasing, or even a minor model update can dramatically shift performance. That’s why a well-structured CI/CD pipeline for LLMs is essential for ensuring stability, reliability, and continuous improvement.
I’ve spent a lot of time refining the best way to handle CI/CD for LLMs, and these are the key principles I always follow. If you’re building an LLM-powered app and want to avoid unpredictable failures, these best practices will save you a ton of headaches.
1. Treat Models, Prompts, and Data as First-Class Citizens in Version Control
Traditional CI/CD primarily focuses on code versioning, but in an LLM app, the model, prompts, and datasets are equally (if not more) important than the codebase itself. A model update can change behavior in subtle ways, so if something breaks, you need to be able to track and revert changes easily.
Best practices:
Model versioning: Use tools like DVC (Data Version Control) or Weights & Biases to track model versions alongside code. Store model checkpoints with metadata on changes.
Prompt versioning: Maintain a structured prompt repository where every variation is logged and tested before deployment. A minor wording change can significantly alter output behavior.
Dataset versioning: Changes in your training or retrieval datasets can cause output shifts. Track dataset updates using tools like DVC or Delta Lake to ensure reproducibility.
Tie everything together: Use Git tags or commit messages to link specific models, prompts, and datasets to code changes so you always know what’s running in production.
2. Automate Model Evaluation & Testing
Unlike traditional software, where you can write unit tests with predictable outputs, testing an LLM is tricky because its responses are non-deterministic meaning they can vary slightly even with the same input. You need a mix of automated checks and human-in-the-loop evaluation.
Best practices:
Baseline regression testing: Store a set of "gold standard" responses and automatically compare new model outputs against them. If a model update deviates significantly, flag it.
Statistical & metric-based testing: Use metrics like BLEU, ROUGE, perplexity, or BERTScore to measure output similarity and consistency.
Bias & safety testing: Run automated tests to check for biased or harmful responses, especially if your model is used in sensitive applications (e.g., customer support, healthcare).
Scenario-based testing: Design test cases for different user scenarios to ensure the model performs well across various edge cases.
Human-in-the-Loop review: Some model updates require human validation. Use a feedback collection system where annotators review a subset of responses before full deployment.
3. Use Canary Deployments & Shadow Testing Instead of Instant Rollouts
Deploying a new model version to all users at once is risky. A bug in traditional software might cause a feature to break, but a flaw in an LLM model can lead to inaccurate or misleading responses, which can damage trust.
Best practices:
Canary deployments: First release the new model to a small percentage of users (e.g., 5%) and monitor performance before expanding.
A/B testing: Serve responses from both the new and old model simultaneously and compare user engagement metrics. If the new model underperforms, roll it back.
Shadow testing: Before making a model live, have it run in the background on real user queries without actually responding. Compare outputs against the current production model for quality assurance.
Kill switch for rollbacks: Always have an instant rollback mechanism in case something goes wrong. You don’t want to be scrambling to fix a broken model in production.
4. Monitor Model Performance Continuously
An LLM’s performance can drift over time due to changing data distributions, evolving user behavior, or subtle biases creeping in. CI/CD for LLMs doesn’t end at deployment you need constant monitoring.
Real-Time quality monitoring: Track response accuracy, relevance, and coherence using automated scoring models.
Drift detection: Use embedding-based comparison methods (e.g., cosine similarity) to detect if model responses are shifting from expected behavior.
User feedback integration: Collect feedback from users on whether responses were helpful or not and use it to trigger re-training if needed.
Latency & cost monitoring: Keep track of inference speed and API costs to ensure performance remains optimal. LLMs can be expensive to run, and a sudden increase in latency or token usage can be a red flag.
Incident alerts: Set up alerts if output quality drops below a certain threshold, allowing you to investigate before users start complaining.
5. Automate Documentation & Collaboration
LLM apps are complex, and multiple teams (developers, ML engineers, product managers, and even legal teams) often collaborate on them. If processes and decisions aren’t well-documented, things can get messy fast.
Best practices:
Automate model changelogs: Use scripts to generate automatic changelogs every time a new model version is deployed.
Maintain a prompt registry: Keep a structured database of prompts and how they’ve changed over time. This helps in debugging when output shifts unexpectedly.
Use experiment tracking tools: Platforms like Weights & Biases, MLflow, or ClearML help in logging model training details, dataset versions, and hyperparameters.
Final Thoughts
Setting up CI/CD for LLM apps isn’t a "one-and-done" task. Unlike traditional software, LLM applications evolve continuously based on new data, prompt changes, and model fine-tuning. The best CI/CD pipelines are designed to adapt.
By following these best practices versioning everything, automating evaluations, deploying cautiously, monitoring actively, and maintaining solid documentation you can ensure your LLM apps remain stable, scalable, and high-quality.
Have questions or want to discuss how to tailor these best practices to your specific use case? Drop a comment I’d love to hear your thoughts! 🚀
