


AI Interview Playbook : Comprehensive guide to land an AI job in 2025
Brownie point: It includes 10 Key AI Interview Questions (With Answers).


Breaking into AI engineering in 2025 is no easy feat, but with the right preparation, you can stand out from the competition. Today’s Where’s The Future In Tech guide walks you through the essential skills, tools, and strategies to ace AI interviews and land your dream role.

What You’ll Learn
Cracking an AI interview requires expertise in machine learning, deep learning, and AI engineering tools. Here’s what we’ll cover:
Core AI Engineering Skills – Programming, ML/DL fundamentals, and system design.
Essential AI Tools – Frameworks, deployment tools, and cloud platforms.
10 Must-Know Interview Questions – Covering key AI concepts and problem-solving strategies.
Latest AI Job Openings – Insights into current hiring trends and where to apply.
AI Engineering Fundamentals
A strong foundation in AI engineering requires a mix of programming skills, mathematical intuition, and deep learning expertise. Let’s break it down:

Programming & Algorithms
Proficiency in programming is a fundamental skill for AI engineers. Here’s what you need to focus on:
Python: Master libraries like NumPy, Pandas, Matplotlib, and Scikit-learn for AI development.
Data Structures & Algorithms (DSA): Strong knowledge of linked lists, trees, graphs, dynamic programming, sorting algorithms, and their applications in AI.
Object-Oriented Programming (OOP): Understanding classes, inheritance, and design patterns in Python or Java.
Parallel & Distributed Computing: Working with CUDA, TensorFlow distributed strategies, and Spark for scalable AI solutions.
Machine Learning & Deep Learning
A solid grasp of ML and DL principles is critical for AI engineering interviews. Ensure you understand:
Supervised & Unsupervised Learning: Logistic regression, decision trees, SVMs, clustering techniques (K-Means, DBSCAN), and dimensionality reduction (PCA, t-SNE).
Deep Learning Architectures: Understand CNNs, RNNs, LSTMs, Transformers (BERT, GPT), and diffusion models.
Optimization Techniques: Gradient Descent, Adam, RMSprop, learning rate scheduling, and second-order optimization methods.
Model Evaluation: Precision-recall tradeoff, AUC-ROC curves, F1-score, and confusion matrices.
Hyperparameter Tuning: Bayesian optimization, Grid Search, Random Search, and AutoML techniques.
Mathematics for AI
Mathematics plays a crucial role in AI development. You should have a strong command over:
Linear Algebra: Matrix operations, eigenvalues, singular value decomposition (SVD), and tensors.
Probability & Statistics: Bayesian inference, Markov chains, probability distributions, expectation-maximization.
Optimization: Convex optimization, regularization techniques (L1/L2), and loss function derivations.
Information Theory: Entropy, KL divergence, and mutual information in AI models.


System Design & MLOps
As AI models scale, system design and deployment become critical. Key topics include:
Scalable AI Architectures: Microservices, event-driven architectures, and distributed model training.
Model Deployment: Using Docker, Kubernetes, and CI/CD pipelines for serving AI models.
Data Engineering: Preprocessing pipelines, feature stores, and handling streaming data with Kafka.
Model Monitoring & Retraining: Ensuring models remain accurate over time with data drift detection and continual learning strategies.
AI Tools & Frameworks You Should Master
Machine Learning & Deep Learning Frameworks
TensorFlow & Keras: Industry standards for deep learning.
PyTorch: Preferred in research and rapid prototyping.
Scikit-learn: Core ML toolkit for classical algorithms.
XGBoost & LightGBM: State-of-the-art gradient boosting models.
Hugging Face Transformers: NLP and generative AI frameworks.
Data Engineering & Processing Tools
SQL & NoSQL databases: PostgreSQL, MongoDB, and vector databases like FAISS.
Apache Spark & Hadoop: Handling large-scale data processing.
Feature Stores: Feast, Tecton, and Databricks for managing ML features.
MLOps & Model Deployment
Docker & Kubernetes: Deploying and orchestrating AI models at scale.
MLflow & Kubeflow: Experiment tracking, model versioning, and pipeline automation.
CI/CD Pipelines: Automating AI deployments with GitHub Actions, Jenkins, and ArgoCD.
Cloud Platforms for AI
AWS SageMaker, Google Vertex AI, Azure ML: Cloud-based AI development.
Hugging Face Hub: Hosting and fine-tuning pre-trained models.
Ray & Dask: Distributed computing for large-scale AI training.
Model Monitoring & Explainability
SHAP & LIME: Interpretability tools for debugging AI decisions.
Prometheus & Grafana: Real-time AI system monitoring.
ML Observability: Tools like Fiddler AI, WhyLabs, and Arize AI for model drift detection.
10 Key AI Interview Questions (With Answers)
Q1. What are the assumptions behind linear regression?
Ans: Linear regression relies on several key assumptions to ensure the validity of its results. Here's a breakdown:
Linearity: The relationship between the independent variables (features) and the dependent variable (target) is linear. This means that a change in an independent variable leads to a proportional change in the dependent variable.
Independence: The errors (residuals) are independent of each other. This means that the error for one data point does not influence the error for another data point. This assumption is particularly important for time-series data.
Homoscedasticity: The variance of the errors is constant across all levels of the independent variables. In simpler terms, the spread of the residuals should be roughly the same for all predicted values.
Normality: The errors are normally distributed. This assumption is primarily important for hypothesis testing and confidence interval calculations.
No Multicollinearity: The independent variables are not highly correlated with each other. High multicollinearity can make it difficult to determine the individual effect of each independent variable on the dependent variable.
No Endogeneity: there is no correlation between the independent variables and the error term.
Q2. How would you build a valuation model for real estate with limited data?
Ans: Given the limited dataset size, a complex, deep learning model might overfit. Instead, we'll focus on models that handle small datasets well and allow for feature importance analysis. We will take these steps:
Data Exploration and Preprocessing: Understand the data, handle missing values, and scale/normalize features.
Feature Engineering: Create meaningful features from the thousands of data points.
Model Selection: Choose a suitable model, considering the dataset size and complexity.
Model Training and Evaluation: Train the model and evaluate its performance.
Feature Importance Analysis: Understand which features are most impactful.
Implementation Methodology
Data Exploration and Preprocessing (Python using Pandas and Scikit-learn).
Feature Engineering.

Model Selection
Considering the small dataset, we'll use models that are less prone to overfitting and provide feature importance:
→ Random Forest: Robust to outliers and provides feature importance.
→ Gradient Boosting (e.g., XGBoost, LightGBM): High performance and feature importance.
→ Lasso Regression: Performs feature selection by shrinking coefficients of less important features.
Model Training and Evaluation.
Feature Importance Analysis.

Q3. How do you handle imbalanced classification problems?
Ans: To handle imbalanced data in a classification problem, following techniques can be used:
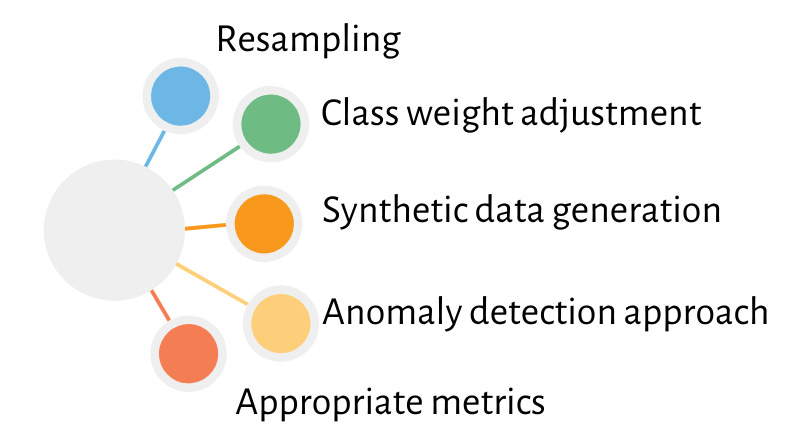
Resampling
Class weight adjustment
Synthetic data generation
Anomaly detection approach
Appropriate metrics (F1-score, precision-recall AUC instead of accuracy).
Q4. Explain backpropagation in neural networks.
Ans: Backpropagation calculates gradients by propagating error backward through the network using the chain rule. The process:
Forward pass: Input data passes through the network to produce output.
Calculate loss: Compare output with actual values to determine error.
Backward pass: Compute gradients of error with respect to each weight.
Update weights: Adjust weights in proportion to their contribution to error.
Q5. How does the Transformer architecture work?
Ans: The Transformer architecture is based on a self-attention mechanism that allows models to process entire sequences in parallel, unlike RNNs. It consists of:

Encoder-Decoder structure – The encoder processes input sequences, while the decoder generates outputs (used in tasks like language translation).
Multi-Head self-attention – Enables the model to focus on different parts of the input simultaneously.
Positional encoding – Injects order information since transformers don’t have sequential dependencies like RNNs.
Feedforward layers – Fully connected layers after attention mechanisms for deeper representations.
Layer normalization & residual connections – Helps stabilize training and improve gradient flow.
Q6. What’s the difference between batch, stochastic, and mini-batch gradient descent?
Ans: For applications where false positives are costly (e.g., spam detection), prioritize precision. For applications where missing positive cases is costly (e.g., fraud detection, medical diagnosis), prioritize recall. Consider business impact when choosing which to optimize.
Q7. How do you optimize hyperparameters in deep learning models?
Ans: Bias is error from simplified assumptions, while variance is sensitivity to training data variation. High bias leads to underfitting; high variance leads to overfitting. Balance using cross-validation, regularization, ensemble methods, and appropriate model complexity for your data size.
Q8. How do you handle catastrophic forgetting in continual learning models?
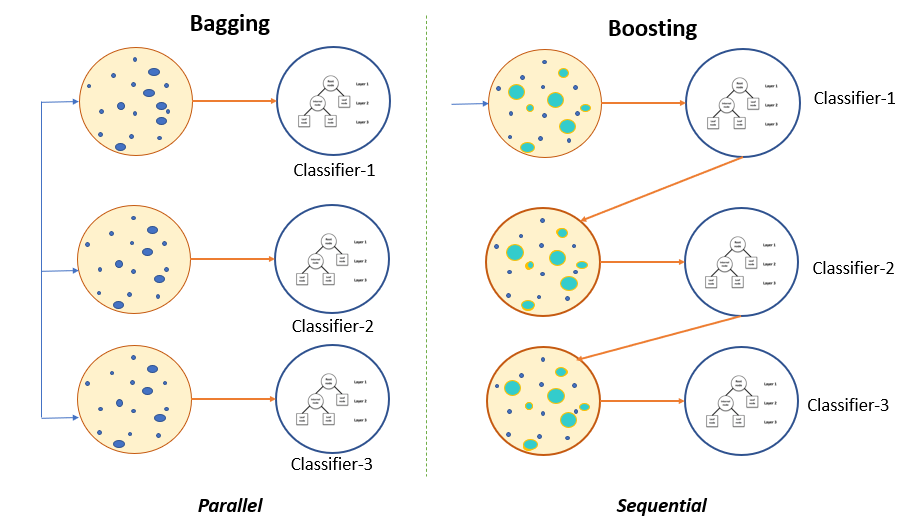
Ans: Bagging (Bootstrap Aggregating) trains models in parallel on random subsets of data and averages results to reduce variance. Boosting trains models sequentially, with each new model focusing on previous models' errors, reducing bias but potentially increasing variance.

Source
Q9. What’s the role of embeddings in AI?
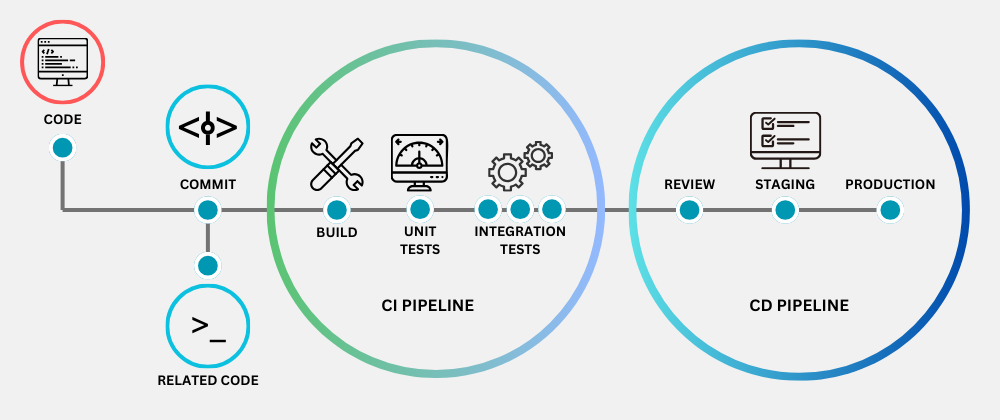
Ans: Deployment process:
Containerize model with dependencies using Docker
Implement CI/CD pipeline for testing and deployment
Use orchestration (Kubernetes) for scaling and management
Consider model serving options (REST API, batch processing)
Monitoring strategy:
Track prediction drift (shifts in model outputs)
Monitor data drift (input distribution changes)
Track performance metrics (accuracy, latency)
Set up alerts for degradation and automated retraining


{kind=link}
Source
{kind=link}
Q10. How would you design a scalable recommendation system?
1. High-Level Architecture
Key Components:
Code Ingestion & parsing – Code is uploaded via API or Git webhook and parsed into an Abstract Syntax Tree (AST).
AI-Powered code analysis – Uses LLMs (Codex, Code Llama, or fine-tuned CodeBERT) to detect code smells, security flaws, and inefficiencies.
Static & semantic analysis – Combines rule-based tools (ESLint, SonarQube, Bandit) with AI-driven pattern matching.
Automated review & feedback – Provides inline suggestions on GitHub/GitLab pull requests, prioritizing critical bugs.
Continuous learning – Improves over time by fine-tuning on past corrections and developer feedback.
2. Tech Stack
AI Models: Codex, CodeBERT, or GraphCodeBERT.
Analysis Tools: SonarQube, Semgrep, Bandit.
Storage: PostgreSQL (metadata), FAISS (vector search).
CI/CD Integration: GitHub Actions, GitLab CI.
Deployment: FastAPI backend, Redis for caching, Kubernetes for scalability.
3. Scaling Considerations
Optimizations: Parallel processing, Caching, Sharding
Reader’s confidence after reading and understanding important concepts from this newsletter:

Recent AI Job Openings
QUASH Applied AI Engineer
Final Thoughts
AI interviews are demanding, but with structured preparation, you can excel. Keep refining your fundamentals, stay updated with trends, and practice problem-solving consistently.
👉 Follow for more AI career insights and interview tips!